Hexagonal architecture or the Ports and Adapters architecture, is a way to structure your application such that its isolated from infrastructure level concerns. It exposes what’s called Ports (or interfaces in C#) that lay down the contract for what the domain supports for e.g. a port for loading products. Adapters then are simply the implementation of these ports using a certain technology stack. For e.g. load products from an Oracle database or from a web service etc.
Many articles talk about the what of this style but in my view, not enough talk about the how. In this post, I am going to try and show one way to actually structure the solution to be more in line with the hexagonal ports and adapters ethos. This directly comes out of recent refactoring effort we made in our team to refactor one of our production services.
I work for an e-commerce company on a team where we handle the backend restocking of our warehouse. These restocking decisions are data driven. We process around 30k+ products that our domain is directly responsible for managing, out of our entire assortment, everyday and calculate their reordering levels. These processed products are then sent via asynchronous messaging to another service, that runs through these products and converts them into purchase proposals for restocking those products. Its a fairly distributed architecture with around 6 services involved in the entire end to end flow.
The reordering level calculation although fairly simple relies on a lot of data, most of which lives in our central Oracle database and some lives on our Raven cluster (both these stores are on-prem while all our services are on AWS).
The first version of the service architecture looked like this:
The use case in our domain will reach out to various “services” to gather all sorts of data from various sources and then enrich the base product with it. It will then perform the reorder level calculation for each product and publish it out to our downstream service via Amazon SNS – a publish subscribe mechanism.
We structured our solution to have technology specific adapter assemblies to such an extent that it was difficult to tell simply by looking at the structure what this service did. It became all about the technology stack and the domain kinda got overshadowed.
The orchestrating use case in the domain model looked somewhat like this:
| namespace Domain | |
| { | |
| public class UseCase | |
| { | |
| private readonly IAdditionalDataA _serviceA; | |
| private readonly IProductService _serviceB; | |
| private readonly IAdditionalDataC _serviceC; | |
| private readonly IAdditionalDataD _serviceD; | |
| private readonly IAdditionalDataE _serviceE; | |
| private readonly IAdditionalDataF _serviceF; | |
| private readonly IPublisher _publisher; | |
| public UseCase( | |
| IAdditionalDataA serviceA, | |
| IProductService serviceB, | |
| IAdditionalDataC serviceC, | |
| IAdditionalDataD serviceD, | |
| IAdditionalDataE serviceE, | |
| IAdditionalDataF serviceF, | |
| IPublisher publisher) | |
| { | |
| _serviceA = serviceA; | |
| _serviceB = serviceB; | |
| _serviceC = serviceC; | |
| _serviceD = serviceD; | |
| _serviceE = serviceE; | |
| _serviceF = serviceF; | |
| _publisher = publisher; | |
| } | |
| public async Task Process() | |
| { | |
| var dataA = await _serviceA.GetDataA(); | |
| var products = await _serviceB.GetProducts(dataA); | |
| var dataC = await _serviceC.GetDataC(dataA); | |
| var dataD = await _serviceD.GetDataD(dataA); | |
| var dataE = await _serviceE.GetDataE(dataA); | |
| var dataF = await _serviceF.GetDataF(dataA); | |
| foreach (var product in products) | |
| { | |
| product.CalculateReorderLevel(dataC, dataD, dataE, dataF); | |
| await _publisher.Publish(product); | |
| } | |
| } | |
| } | |
| } |
A lot of code has been removed for brevity (and service names have been dummified), in real life this use case class was more than 200 lines of C# code.
Because of the way the data is structured and set up in Oracle in our organisation, we had created a port interface around each of these queries and added those as the dependencies of our use case. The domain layer got filled with lots of these little internals specific interfaces, IThisService and IThatService. Classic Conway’s Law in action.
Things got interesting when a couple of weeks ago we had to add more queries to the service and we started off following the same pattern. Alistair Cockburn, the inventor of Hexagonal architecture, advocates for maximum 4-5 ports per hexagon but with these queries we were well on our way to have 8.
What if few months from now we have a different data storage engine for e.g. AWS RDS and we no longer have a need for multiple queries?** . Perhaps we’ll find a way to optimally retrieve data with just one or couple of queries? We will then not only have to write RDS specific adapter assembly but also either eliminate a bunch of interfaces from our domain layer or litter the RDS implementation with a bunch of unimplemented query methods. Violates Interface Segregation Principle.
This would also have a knock on effect on our use case which orchestrates all these operations. Its completely contrary to the idea of the Ports and Adapters style. Use case doesn’t care that you need to run 17 queries in order to get the data, its job is to execute business rules of your domain and that’s what makes you money. Accessing data for a specific function is the adapter’s job.
We realised we had to refactor*** a service that’s already in production to eliminate this kind of “abstracted coupling” and maintain the testability of the service all the while simplifying the use case.
One of the key insights of this style of architecture is that the ports and by definition the adapters are for carrying out a specific domain function and they are never about the technology itself. So the fact that we needed to execute these half a dozen queries to get all sorts of additional data in order to eventually calculate reorder level, is an internal detail of a much coarser operation i.e. get active products. So why not encapsulate all that complexity behind a single port i.e. interface? Think the Facade design pattern. So that’s what we did!
We moved all these mini data services into the adapter that retrieved active products and because all the additional data belonged to the product entity anyway, it made sense for it all to be unified behind a single interface. We still kept the data methods in separate classes for maintainbility but they were no longer implementations of their own interfaces.
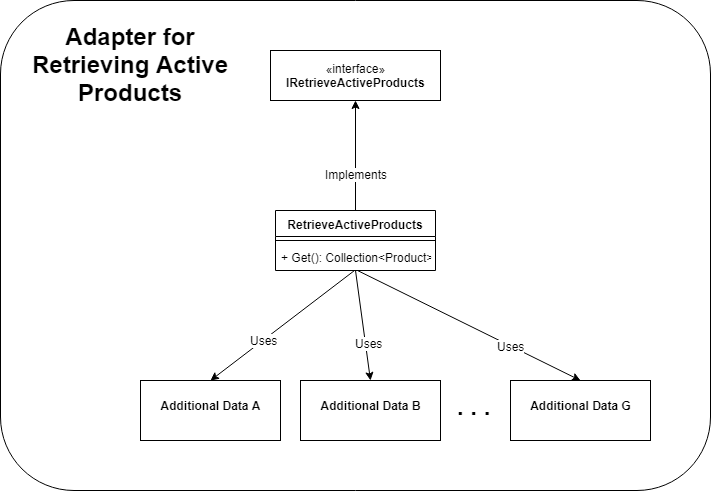
The use case then only gets a collection of fully hydrated products that it can then calculate reorder levels for. Getting rid of a lot of faux ports resulted in about 75% reduction in code volume in this class alone.
| namespace Domain | |
| { | |
| public class UseCase | |
| { | |
| private readonly IPublisher _publisher; | |
| private readonly IRetrieveProducts _productsRetriever; | |
| public UseCase( | |
| IPublisher publisher, | |
| IRetrieveProducts productsRetriever) | |
| { | |
| _publisher = publisher; | |
| _productsRetriever = productsRetriever; | |
| } | |
| public async Task Run() | |
| { | |
| var products = await _productsRetriever.Get(); | |
| foreach (var product in products) | |
| { | |
| product.CalculateReorderLevel(); | |
| await _publisher.Publish(product); | |
| } | |
| } | |
| } | |
| } |
The new structure post refactor looks like this:
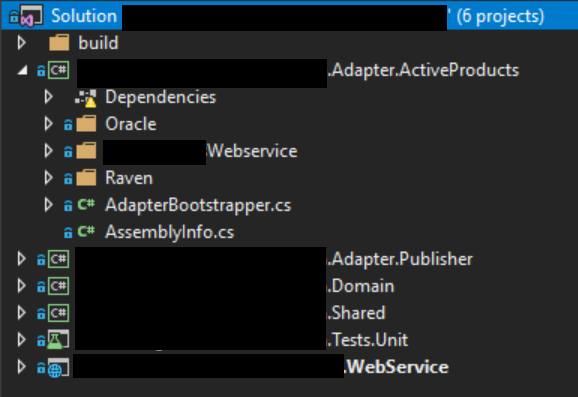
We also got rid of technology specific adapter assemblies because they can very quickly grow out of control. Its much simpler to just create technology specific folders within an adapter that’s structured by the function it serves. Although, if you have a good enough reason to have separate assemblies and can retain testability and domain function visibility, then by all means have separate assemblies. Having dozens of technology specific packages in one assembly is also bit of a problem.
We also refactored the domain namespace a bit to tidy it up and make it’s structure more meaningful:
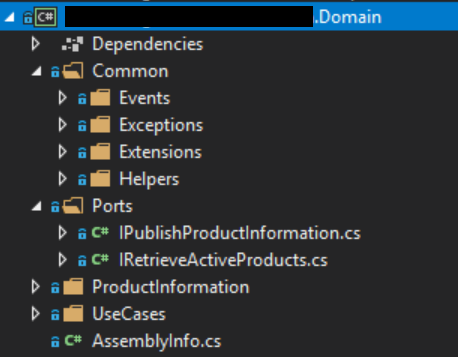
The solution structure now reads much better, you can get some idea about what the application does, just by looking at it.
The port/interfaces follow a role based naming style for e.g. IRetrieveActiveProducts rather than IActiveProductsRetriever. This is just a convention we are trying to follow on my team because it reads more naturally.
Our tests became more about the behaviour and use case rather than lots and lots of internal specific unit tests:
| public class WhenRunningProductReorderLevelUseCase | |
| { | |
| [Fact] | |
| public async Task Given_Products_With_Values_When_UseCase_Is_Executed_Then_The_Calculated_ReorderLevel_Is_As_Expected() | |
| { | |
| var testProducts = TestData.SampleProductsWithExpectedReorderLevels(); | |
| var publisherStub = new StubPublisher(); | |
| var activeProductsStub = new StubRetrieveActiveProducts( | |
| testProducts.Select(x => x.OriginalProduct).ToList()); | |
| var useCase = new UseCase(publisherStub, activeProductsStub); | |
| await useCase.Run(); | |
| foreach (var product in testProducts) | |
| { | |
| var publishedProduct = publisherStub.PublishedProducts[product.OriginalProduct.ProductId]; | |
| publishedProduct.Should().NotBeNull(); | |
| publishedProduct.ReorderLevel.Should().Be(product.ExpectedReorderLevel); | |
| } | |
| } | |
| } |
In order to fulfill the dependencies for the tests without worrying about hooking up any real databases, I can now simply create stubs or test adapters and substitute them in for the real adapters and be able to assert on the behaviour:
| internal class StubPublisher : IPublishProductInformation | |
| { | |
| public Dictionary<int, Product> PublishedProducts = new Dictionary<int, Product>(); | |
| public async Task Publish(Product productInformation) | |
| { | |
| PublishedProducts.Add(productInformation.ProductId, | |
| productInformation); | |
| await Task.CompletedTask; | |
| } | |
| } |
Ofcourse architecture evolves throughout the life of an application as we attain a better understanding of our domain over time. This is in no way the culmination of ours either but only a milestone along the way. The important goals to keep in mind to help evolve the architecture in a meaningful way are:
- Testability of the beahviour.
- Isolation from the infrastructure. and,
- Fast feedback loops to see what works and what doesn’t.
Hope this post wasn’t all gibberish and that there was a helpful takeaway or two for people.
**
Although you don’t often change technology stacks willy nilly but it puts the business you work for in an incredibly powerful position to know that they can change and adopt better technology rapidly. We have been ditching RavenDB in favour of DynamoDB as a part of an ongoing migration effort on our team only because much of our service architecture has been designed to allow for that kind of agility. This refactoring experience report is one example of how we do it and how Ports and Adapters style fits the bill.
By contrast, I have also worked on teams where the application was so tightly coupled to the underlying data storage/infrastructure, that this kind of refactoring effort will have taken weeks if not months to finish and it would have had a high probability of failing on day one.
***
Refactoring a production service is no small task so its better to do with the rest of the team in a mob-programming style. With people watching over you, you will be surprised the kind of simple things they will catch that you will overlook. In my experience there is no better way of sharing knowledge in a team and learning from each other, than mob programming. Worth doing it. We were able to refactor the service’s entire internal structure in less than 4 hours and went to production successfully soon after.

Nice, Aman! I shared it with some colleagues, so they can see how we designed the applications at Coolblue.
Sure! hope it made some sense. Feedback is always welcome.
Hello. From the drawing I guess your port for retrieving data is a driver port? If so, I can’t see any driver adapter using that port. On the other hand I see that the use case (wich is inside the app) uses that port. The hexagon doesn’t use driver ports, but implement them. Or maybe I don’t understand what you mean and the port for retrieving data is a driven port although it is drawn at the left? It isn’t very clear for me to see the elements and the dependencie. Regards.
Thanks for your comment/question Juan.
The way I understand Ports and Adapters architecture (and I could be wrong, so please feel free to correct me and I will update the post) is that ports are the behavioural interfaces that the domain exposes and adapters implement those interfaces. There are input adapters/ports (for e.g. retrieving data from various sources to do some processing) and there are output adapters/ports (for e.g.for saving the result of the processing to a database or for publishing a message on a queue etc). The diagram that I have drawn shows input on the left, processing in middle and output on the right.
I am not quite sure what you mean by “driver ports”. If it means the thing the initiates the “transaction”, then in my case, its a REST endpoint which can be equally invoked by human users or other systems (I suppose you can call them the ultimate drivers!). I just haven’t shown that in the diagram. Once the request lands at the controller, the use case which is the part of the domain as represented by the inner hexagon, is activated and uses these input ports to retreive data, calls the inner domain operations to operate on that data and ultimatey uses output ports to send results out.
Does that answer your question any bit?
Hi, yes reading your answer now understand your implementation.
But from my point of view, I think you are wrong in the concepts. You should draw retrieving data port on the right. What you call input and output ports are both driven ports (they are interfaces of the app implemeted by external adapters, one for reading a db and another for writing in a db, but both are driven, i.e. the app initiates the interaction).
On the other hand, a driver port is an interface offered by the app to the outside world. Driver ports are use case interfaces. A driver port isn’t implemented by an adapter, but by the inside of the app. In the driver side (the left side), the external adapter calls the driver port. The driver adapter in your case is the REST controller.
I explain the pattern in my article:
https://softwarecampament.wordpress.com/portsadapters
Take a look if you want. I’m preparing an example in Java 9 with modules which I will upload to github.
Regards, Juan.
You’re right, the driver port in my case is simply a REST controller but since the controller is implicitly also an adapter that converts a network request payload into an actionable command for the use case, there is no point drawing it out in the diagram.
Depending on the application, you might choose to show one zoom level higher or lower. In my case, there is no UI, the tests “driver” can invoke the use case using test adapters or mocked out “driven ports” as you call it and assert on the results of the behaviour. We generally don’t write tests or mock adapters for REST controllers because there is hardly any logic in our controllers and the adaptation of JSON to a model that the domain can work with, is implicit, we simply delegate incoming actions to the appropriate use case. So by extension, if we are able to test our use case with appropriate test adapters and maintain the purity of the domain from any infrastructure concerns then that’s all we need. Essentially, we are both talking about the same thing here may be the difference is in what we call things.
I certainly like the way you have structured your diagram, driver and driven sides show a clean separation, its just that in my case the driver side is pretty thin and almost not worth showing. Also, a great post that I have bookmarked for later reference.