
In this somewhat of a long post, I will go over some of the lessons I and my team learned while building an event driven architecture at work, why did we build it, recommendations and watch-outs for anyone else thinking of doing the same. This is more of a field report from a real life environment so there is a generous helping of pragmatism around architecture and careful and deliberate avoidance of dogma and purism. I am sure there are better or different ways of doing this but this has worked well for us so far.
I work in the Restocking domain at an e-commerce company and we build systems for our Stock Planners to allow them to make accurate stock planning & purchasing decisions. Its crucial for them to work with as accurate data as possible so our systems need to cater for that.
We started work on this project back in March 2019, the goal of this project was to eliminate a lot of manual work involved in reviewing a lot of pending stock purchase orders (mostly in the legacy system), remembering to cancel or postpone them under certain conditions and inform suppliers of it all.
A system was envisioned that will review purchase orders that stock planners had placed to restock the warehouse, and create suggestions based on certain set of criteria, for e.g. if a purchase order is very old, then recommend to cancel etc. These suggestions will be offered to the users everyday so they can hit just one button to handle them which, in the background, will initiate the submission workflow of updating the central database before sending e-mails to suppliers. Basically one-click distributed transaction! 🙂
Our product owner would often use words like, “…evaluate the purchase orders stock planners place or change, in real time. Oh and also, when the stock arrives at/leaves the warehouse we need to adjust our suggestions accordingly and when a purchase order is finished then we need to process that accordingly as well…”. Any time you hear “When x happens, we need to do y” from a Product Owner – it usually means that the domain is naturally reactive, expects us to respond to events and therefore an event driven architecture might be the right fit.
There was just too much data change dance back and forth for it to be an effective and efficient batch driven system anyway. We’d have been doing too much database querying and coupling ourselves ever deeper with the big monolithic central database.
Now, I am talking about an event driven system but not necessarily an event sourced one using ES/CQRS. Those patterns come in handy when :
- You need to be able to reconstruct the state of the aggregate from any point in time in the past to any point in time in present/future by replaying events. Financial auditing and legal compliance needs will drive architectures into this direction for e.g. banking and investment firms where they want an audit trail of events. This is also useful from a disaster recovery standpoint.
- You need really high scale and throughput indeed which necessitates an append only event store and you don’t update or delete anything. The obvious downside to this is that you can’t just replay all events from 0 to n everytime you need to get to an instantaneous snapshot of the aggregate, that will be incredibly inefficient and wasteful if you have millions of events to churn through. To counter this, you need to implement checkpointing i.e. after every x events, you assemble a snapshot with events up until that point and store the state. This certainly adds a lot of complexity to the architecture so you really need to make sure that the benefit will justify the costs.
- Your read and write models are drastically different and change at different rates with read model projection being a computationally intensive process which is going to be done asynchronously and in an eventually consistent way. For e.g. running heavy financial reports that can take hours would benefit from the CQRS style architecture where the reports are generated asynchronously from all the events and converted to read only projections. Users of this domain naturally expect eventual consistency.
None of our use cases fit any of those needs at the moment so we couldn’t justify the costs of building such an architecture. Right from the start we had estimated the number of events to be anywhere around 40k-50k every day. Eventually this turned out to be the right choice and a fairly accurate volume estimation.
The aggregates that we build from these events tend to be short lived (i.e. once they are handled by the users, they are as useful as dirt) such that we never need to replay events from the past to reconstruct the aggregate nor we have any audit trail requirements for this kind of automation workflow. We do log a lot of these events and these logs are retained for about 30 days which is plenty of time to do any historical analysis on the data, just not state snapshot reconstruction.
Lesson 1: Don’t fall into the trap of over-engineering an evented solution using ES/CQRS from the get go. See if the problem domain benefits from such a pattern.
Event Driven Back End:
We started by defining the domain model for this problem context and writing unit tests to start verifying our assumptions and find hidden ones. We also defined the structure of the events that we needed to listen for and how each of these events will be handled. At this point we didn’t really care how these events will be delivered to us. As a matter of fact, worrying about specific infrastructure at that early a stage is almost sure to paint you into a corner because you’ll have made decisions that will end up having long term negative impact on the architectural health of system. We knew that the events will be pushed onto a message queue of some sort that we’ll have to listen on.
We also didn’t bother with external libraries/frameworks/nuget packages that do event dispatching because that would have introduced too much complexity too soon with practically no advantage.
Many Meanings of Event Driven:
Martin Fowler categorises event driven systems into 4 categories.
We had already ruled out Event Sourcing, as I mentioned above, so we went for the following hybrid event styles for various domain entities:
- Product information -> Event Carried State Transfer (We published the entire product information for e.g. sales forecast, reorder levels etc as an event message because this information only gets published once a day and then throughout the day doesn’t change at all, just the way our domain works.)
- Purchase orders changes -> Change Data Capture + Event Notification (The owning team published one event for the changes to the existing entities and one event for when a new entity got created. For the new entities, only the id was published which meant that we can go and query further state information via a service call using that id.)
- Stock level changes -> Change Data Capture (Stock level goes up and down in the warehouse tens of thousands of times a day, so we had the product id and stock change published which we can then apply to our domain entity and be consistent with the actual change without needing the full state.)
The common theme across all these events is that they are all immutable, they are a record of something that has already happened in the past. In real non-Hollywood life, you cannot change the past (and by extension neither the event). To correct a mistake introduced by one event, you could issue a rectification event which will follow the usual handling and ensure state is consistent.
Request Response Driven Front End:
All these events will help us create the suggestions and store them somewhere but in order for them to be consumed by the users they have to be delivered to them via a UI, so we chose to build the entire backend separate from the application which hosted the frontend. The front end app will then simply talk to the REST API that the backend will expose, to fetch and handle suggestions. This way we could also stop faults in the backend from propagating into the front end application.
In order to keep the architecture from getting too distributed and complex, we chose to put the REST API and the background event queue listeners in the same process. We were able to leverage the new BackgroundService model available in ASP.NET Core 2.1 to achieve this. It did mean that the bootstrapping of the overall application became a bit complicated because we couldn’t put all dependencies in a single DI container because the BackgroundService is forced to be a singleton which means all the dependencies it needs, also need to be registered as singletons. This in turn meant we couldn’t put shared dependencies with different lifetimes in the same container (which makes sense).
The way we got around this was by having 2 DI containers (we used SimpleInjector cross wired with the ServiceCollection DI), one for transient/scoped registrations for the web service dependencies and the other for singleton registrations for the BackgroundService instances. Shared dependencies then had to registered twice once in the singleton container and once in the transient/scoped container.

This model though confusing initially, actually worked fairly well in practice as long as we made sure that the lifetime of the dependencies were consistent with expected scope. Key is to have thread-safe singletons.
We logged a lot of these kinds of architecturally significant decisions (for e.g. separating the service that does the suggestion generation from the service that parcels them off to suppliers) into an Architecture Decision Record which we pushed into source control to have a revision history and point of reference for when six months down the road we wonder, “why the hell did we just use one queue?” or “Was it a concious decision to use Lambdas/Serverless for this service or were we just pulled into the cool stuff?”
Lesson 2: Start developing your system inside out, focussing on the domain. Start out with a simple architecture. Document your significant architectural decisions!
Next, we started looking for the sources of these events and this is where a lot depends on your organisation, how teams are structured, what kind of systems they build and how they communicate. For e.g. some of the events that we needed, were already being published to a pub/sub mechanism while others had to be created because the teams that owned that data didn’t have any need for events until we came along. In some other cases still (for e.g. stock level changing in warehouse), there was no API yet that could push those events to us so we had two options: wait for the service for a few months or hook straight into the central database and publish to an Oracle Advanced Queue. We went for the second approach.
We chose to build our application architecture using the Hexagonal ports and adpaters style which allowed us to push all these various infrastructure nitty-gritties outside the application core by building technology specific adapters and only use the port interfaces from within the domain to interact with them. This way we can swap for e.g. the Oracle Advanced Queue based implementation for a pub/sub based implementation when one became available. Having a clean separation between the inside and the outside of your application is crucial to allow your team to defer certain technical decisions until the last responsible moment.

Event schema was another problem that we had to address as early as possible. We spoke to the relevant teams and established a mutually compatible contract for the events. Because we chose to go for a fan-in model for event subscription i.e. all these different events will be pushed to the same event queue, we needed a way to distinguish between them so we had to ask the publishers to include a custom header in the message envelope which was set to a mutually agreed upon value per event. Our subscriber adapter will then look at this header and dispatch the event to the appropriate handler. Pub/Sub events are meant to cater for the needs of the many so they shouldn’t have subscriber specific data otherwise it will make the event too coupled to a specific subscriber.
It took us couple of months to source all these events from different teams but having a standardised way to add events meant that adding additional events in the future will be relatively easy.
Lesson 3: Understand how your organisation works and how various teams work. Design your application architecture to be able to better absorb organisational/infrastuctural changes and upsets and keep your domain immune from such changes. Try Ports and Adapter architectural style and keep your event handlers in the domain. Consider a fan-in approach to start with, too many queues can be quite complicated.
One of the key expectations from this solution was fault tolerance and recoverability, i.e. in case of service failure, data shouldn’t be lost and the service should be able to resume work where it left off, when it comes back up. Reactive systems use external message queues to buffer and process the events which makes them a more fault tolerant option compared to batch driven systems which rely on in process state which is susceptible to being lost in case of an outage.
It also allows us to scale the system horizontally to increase message processing throughput as opposed to a batch system which is restricted in scaling often because of some transient in-process state and potential for state corruption with multiple instances involved. With messaging architectures, messages can be guaranteed once only delivery but to be on the safe side, we ensured that message processing was idempotent i.e. processing a message, say 10 times, will yield the exact same result as processing it once. This can be achieved by doing an UPSERT operation or only inserting if a record doesn’t already exist, depending on your use case. This also affords a reactive system recoverability because the whole operation can simply be retried with reasonable certainty that already processed messages won’t be affected.
For every Yin there is a Yang, for every queue there is a dead letter queue– the queue that holds the messages that couldn’t be processed. Managing a DLQ is highly dependent on how crucial is that data, how difficult it is to source it again and who owns the source of truth. Most of our events are external events to which we don’t own the source of truth so we can’t just re-queue a DLQ message as that would have business implications if, unbeknownst to us, its source of truth has changed. We’ll just need to wait for correct events to arrive as per normal and get it resolved that way.
There could be occassions when an event doesn’t have a message type header which our system will automatically bounce to the DLQ. The fix for this is to simply have the publishers fix it at their end and then we can decide whether we want to a) Fix the messages in the DLQ and re-queue them or b) drop these messages and go to source of truth, fetch the updated version of the affected purchase orders and back-process just those ones. We are yet to put in place a good DLQ management strategy but its probably going to be one of the 2 options.
We do however, keep a track of which events end up in DLQ via our logging and monitoring dashboards and we always investigate why an event ended up in the DLQ.
The other aspect for fault tolerance is an ability for the users to “self-service” some common failure modes. For this we make sure, that the suggestion handling status is updated on the UI accordingly. For e.g. if the e-mail fails to send, then the UI highlights those suggestions with the reason for failure and gives the users an option to resend.
Server Sent Events help us achieve this status update asynchronously because the suggestion handling is asynchronous i.e. users handle one suggestion and immediately move on to the next one while the suggestion handling happens in the a background thread. The reason to do suggestion handling asynchronously is due to the distributed transaction that we need to do involving multiple systems, we don’t want to do this within the context of the web request because it could affect the UX in a negative way.
To ensure that the system stayed available and fault tolerant, we made sure that there were at least 3 instances of the service one per Availability Zone (in AWS) and we configured auto-scaling to ensure these 3 instances. This way, we can continue operating even if 2 of the 3 instances died suddenly. Another advantage of this was almost even parallel processing of events which maintained a decent throughput without choking any one EC2 instance significantly. Of course auto-scaling is not instantaneous, so it will be a couple of minutes before a new instance will be ready to start processing.
Lesson 4: Think about the overall fault tolerance and performance goals of the systems, upfront. Think about dead letter queue management: ignore vs re-queue vs re-fetch.
Event ordering was another thing we had to think about. Do we have to process events in a certain order i.e. is there a dependency between events? Are all events going to be available at roughly the same time or are they going to be staggered by a quite a bit? How is our use case going to react to all these events flowing in? We couldn’t create a suggestion for a purchase order until both purchase order event and product information events were available and given that these events happen whenever they happen, we had to store them in a database whenever we received them. Because every event coming in triggers the review use case, at some point the review workflow will catch up and generate suggestions with all the input data available.
Race conditions between various events and workflows could lead to consistency problems because of the inherent asynchrony in event driven architectures. We had this problem where a web service we call also generated an event that we subscribed to (I term this an echoed event) and this event arrived before the service call finished. As a result of the event, we would would delete the suggestion (normal behaviour in its isolation) but when the service call returned, the suggestion would be upserted i.e. it would re-create that suggestion if not found, with the state that it knew of when it started (also normal behaviour in its isolation). Coincidentally the state was correct but if the ordering were reversed it would’ve messed up the state and disrupted the workflow.

To solve this we modified the event handler to not delete the suggestion but simply mark it “Complete” but only if nothing else had modified it in the meantime for e.g. a user action. We then scheduled a background job which will sweep the database at a pre-determine non-business hour everyday and delete all suggestions that were handled by the user or marked “Complete”. By taking the delete operation “off line” so to speak, we made sure that all the data that was needed for the workflow was there and in an expected state for as long as needed and will not be affected by these kinds of races.
Another race condition was that the user initiated workflow might get delayed for some reason but in the mean time some other event might come in and alter the state of a suggestion in a way that becomes incompatible with the result of the workflow. In such cases, we chose to give priority to the user actions and ignored the events trying to affect those suggestions.
The third race condition (which is sort of a variant of the one above) was that a user might open a suggestion on the front end app and go for a long coffee break but in the mean time an event might come in and remove the suggestion if its no longer valid. The user then gets back to their desk and tries to handle that suggestion and ends up handling a suggestion that wasn’t even supposed to exist. This would lead to miscommunication with suppliers and overall inconsistent data in multiple systems. In this case, we opted to ignore user action if the suggestion isn’t found. On the UI side, we decided to maintain state snapshot which we updated via Server Sent Events to indicate that that suggestion has been deleted.
Fourth race condition could be when multiple instances of the service are processing multiple events for the same product. For e.g. instance 1 processes the stock increased event while instance 2 processed stock lowered event, then whoever saves their data back to the database last will win overwriting the other instance’s work.
To address this, we added optimistic concurrency control to the domain entities using row versioning. Both instances will then retrieve the same version of the entity, both will update their copies of it and bump up the version, but then while updating if the current version in the database is higher than what’s being attempted to be put in, we throw a RowVersionMismatch exception.
This exception is handled by simply retrying the event which will cause a re-fetch from the database and the update will succeed this time round. Ofcourse, the worst case scenario is that it could go in a death spiral where every retry results in a row version mismatch in which case the event will end up in the Dead Letter Queue.
Lesson 5: Look out for potential race conditions with events and design for consistent state updates. Figure out which among the involved operations are more important, prioritise them and force the others to yield. Do clean-up as an out of band operation.
Building a complex EDA that is a part of a bigger distributed system, is not a trivial undertaking and given that we would be processing upwards of tens of thousands of events of all different types everyday and communicating with other services, it was crucial to know what and how the system is performing. We established the following technical metrics that we could track in our logging and monitoring platforms:
- How many of each type of events are we processing every day?
- What’s the average latency around the handling of these events?
- Since this hybrid service also has a Web API component, we also want to know the request latencies for the most critical endpoints.
- How many user interactions are resulting in failures and how many in success?
- What’s the health status of the overall system and that of the dependencies? I have written about health checks here
- How many messages do we have in the Dead Letter Queue?
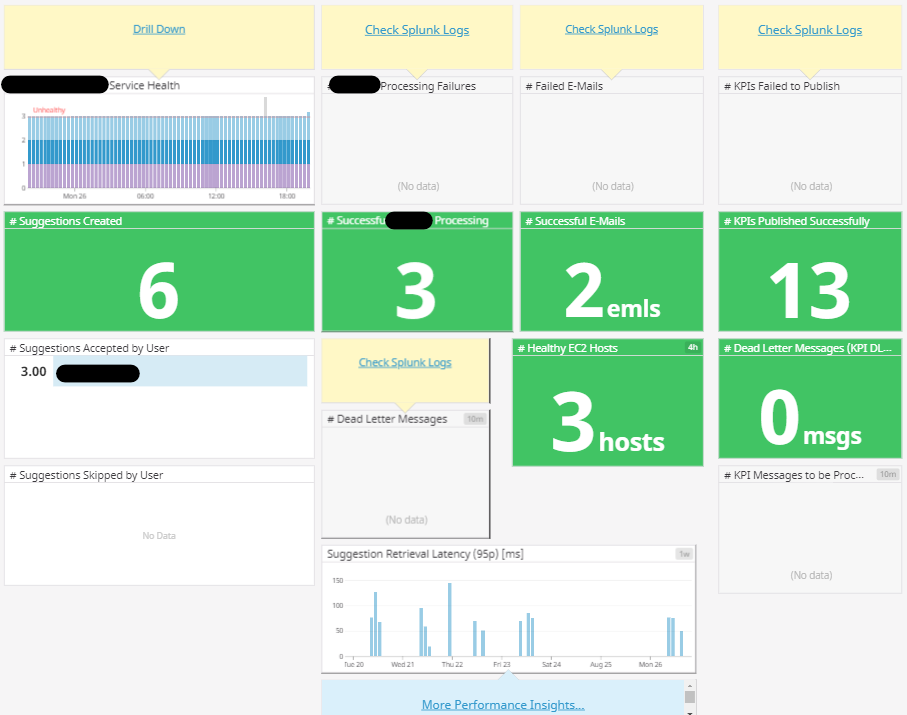
In terms of logging, we stamped each event handler invocation, web api request or anything that’s an entry point into the use cases, with a correlation id from day one and made sure to propagate it to any external services our service might need to talk to. During troubleshooting being able to trace the flow for a given event, could be a life saver because it allows you to follow the chain of events that led to a certain outcome.
Even under non-outage operations, our PO might ask, “hey, user A can’t see the suggestion for this purchase order, the purchase order qualified for a cancellation but the suggestion doesn’t appear. Can we investigate?“, with the right correlation id we can trace the flow from genesis to the end, may be a change in purchase order made by someone caused the old suggestion to be rendered invalid so it was removed and user mistakenly assumed that the suggestion will still be there. In the absence of correlation ids, its a big wild goose chase in the logging system with potentially millions of events to sift through.
We also monitor our systems for anything that could affect the critical path of the overall business workflow. Setting up automated alerts for only when certain key thresholds are crossed for e.g. a dependency service reporting unhealthy for over 30 minutes or on a weekday no stock level change events coming in or an unhandled exception getting logged as an error etc.
Lesson 6: Event driven architectures can be really hard to debug, good logging and monitoring will prove a lifeline. Develop an application landscape dashboard to give you an indication of the instantaneous health and event processing metrics at a glance with an option to drill down further. Set up actionable alerts only for the most critical failures to prevent alert fatigue.
Testing an event driven system is specially hard because in production, events will fly in from all different directions at the same time as database transactions and http service calls might be happening. One unlucky moment and it could easily blow up, and there is no real feasible way to duplicate those kinds of behaviours on your local machine, not without investing in a lot of energy and time into it anyway.
!!!WARNING!!! I am NOT recommending what I am about to say in the next 2 paragraphs, its just something we opted to do given its ease and relatively low risk. If you have a better way, do it and let me know!
No matter how much testing you do, bugs will still sneak past into production! Problems like database columns containing the wrong values because fields in code were switched around or even the introduction of some new columns to our database schema, meant that the data already in the database had to be purged and re-generated after the fix in place. In order to do this on demand, we added temporary admin endpoints to our API, atleast until we got the system in a stable state.
This might sound like a big destructive way to fix these kinds of problems but for us actually it proved pretty safe because a) For most data, we didn’t own the source of truth and relied on events to generate local state b) the state that we did own the source of truth for i.e. Suggestions, we can simply regenerate them if users hadn’t handled them, with zero impact to the users. If they were handled, then they will be automatically excluded when we ran our system initialiser. This system initialiser was just another background process that will run on system start-up, execute a SQL query to source the data from the central database and populate our local database. We can then let our domain use case loose on this data to generate suggestions from fresh. Start to end, this resetting took no more than 10 minutes.
Having said all that though, we did write a lot of tests sort of following the testing pyramid:
Start with unit tests: We started with unit tests at the domain level (the inner hexagon in the Ports and Adapters diagram you saw above) to assert on the expected behaviour (for e.g. if the purchase order is sufficiently old then does our review use case return a cancellation suggestion?) and get really fast feedback without any dependency graph set up. As long as your domain is not anemic (if its a non-trivial app then it likely won’t be), then writing these unit tests targetting the domain classes will allow you to have tests that test something from day one even without any infrastructure in place. This is simply indispensible.
Test Event Handlers: At a level further up from the fine grained domain use cases and entities, lied our event handlers which would take dependencies on various port interfaces for e.g. purchase order line repository, product repository etc and the domain use case that they needed to invoke. We began by creating simple in memory stub implementations for these ports (the underlying store is just a Dictionary<> for easy look-ups by ids) and injected those into the event handlers in our tests and asserted on the output of the handling of an event. An example of this looks like this (this is the Product event handler):
| namespace Domain.ProductInformation.EventHandlers | |
| { | |
| public class ProductInformationHandler : | |
| IHandleEvents<ProductInformation> | |
| { | |
| private readonly ReviewUsecase _reviewUseCase; | |
| private readonly IStorePurchaseOrders _purchaseOrderStore; | |
| private readonly IStoreProducts _productStore; | |
| public ProductInformationHandler( | |
| ReviewUsecase reviewUseCase, | |
| IStorePurchaseOrders purchaseOrderStore, | |
| IStoreProducts productStore) | |
| { | |
| _reviewUseCase = reviewUseCase; | |
| _purchaseOrderStore = purchaseOrderStore; | |
| _productStore = productStore; | |
| } | |
| public async Task Handle(ProductInformation eventToHandle) | |
| { | |
| var product = eventToHandle.ToEntity(); | |
| await _productStore.Save(); | |
| var purchaseOrderItems = await _purchaseOrderStore | |
| .GetFor(eventToHandle.ProductId); | |
| foreach (var item in purchaseOrderItems) | |
| { | |
| await _reviewUseCase.Execute(item, product); | |
| } | |
| } | |
| } | |
| } |
And the corresponding test looks like this:
| public class GivenThereArePurchaseOrdersForTheProduct | |
| { | |
| [Fact] | |
| public async Task ShouldCreateValidSuggestion() | |
| { | |
| var productId = {use a dummy id}; | |
| // set up the stub to already have a purchase order stored | |
| var poStore = new PurchaseOrderStoreStub() | |
| .WithPurchaseOrder(...); | |
| var productStore = new ProductStoreStub(); | |
| var suggestionStore = new SuggestionStoreStub(); | |
| // initialise the System Under Test passing in all the stubbed dependencies | |
| var handler = new ProductInformationHandler( | |
| new ReviewUseCase( | |
| suggestionStore, | |
| productStore, | |
| poStore), | |
| poStore, | |
| productStore | |
| ); | |
| // invoke the handle method (It doesn't matter if its invoked | |
| // via an event arriving in a queue or by a test suite like this one) | |
| // create a test event with canned values | |
| await handler.Handle( | |
| CreateTestEvent(...)); | |
| // Time to assert on the output of handling the test event. | |
| var savedProduct = await productStore.GetByProductId(productId); | |
| var suggestionForProduct = await suggestionStore.GetFor(productId); | |
| // Assert that incoming product was saved successfully | |
| savedProduct.Should().NotBeNull(); | |
| // Assert that as a result of an appropriate event, the suggestion was also created | |
| // and stored in the "database" | |
| suggestionForProduct.Should().NotBeNull(); | |
| // various other assertions on suggestion attributes. | |
| } | |
| } |
The output from this event handler would be that a suggestion would appear in the in memory store stub which we can assert on. I have experimented with couple of approaches on asserting against an in memory store and I don’t have any favourites:
a) Expose the fields as public/internal so I can assert on its contents for e.g. inmemRepo.Products.Count().Should().Be(1);. After all, its a test with all stubs marked internal so I don’t have any problems exposing the inner state of the stubs as long as it allows me to assert on what I need to assert on.
b) Create extension methods on that specific stub that allows you query its content in a more encapsulated and cleaner way for e.g. inmemRepo.CurrentProductCount().Should().Be(1);
Testing at this level will allow you to exercise the domain in a more coarse grained way i.e. given this input, I expect this output. We followed the same approach with use cases that were invoked by the REST API controllers. We don’t write tests for the controllers themselves because there is little to no behaviour in them other than some custom exception handling. All our controllers simply delegate the execution to the underlying domain use cases so there is no value in writing tests for them IMHO. Hitting F5 and playing in Swagger is sufficient.
Things like web service calls, database persistence logic all will usually have some kind of DTO conversion logic in them (because we don’t serialise our domain entities straight into the database or onto the network but only their flattened representations called – Data Transfer Objects). This conversion logic will map fields from the domain entity to the dto when storing/sending data and back to the domain entity when retrieving it. And therein lies one big gotcha with in memory stubs – by storing direct references to your domain entities in the in-memory stubs – you are not exercising the domain -> dto -> domain conversion logic present in your adapters. This conversion will only be executed when you run the application and do real service/database calls. And anything you forget to run locally or test manually, will be a breeding ground for subtle bugs.
We had this exact bug in one such domain -> dto mapping while calling an upstream service due to which the receiving side got the wrong value in the wrong field. This problem went undetected because both fields were integers so there was no type conversion errors and we had no coverage of the dto conversion logic that would allow us to assert on the outgoing values to make sure they were what we expected. Strategies like Contract Testing and Consumer Driven Contracts while beneficial, cannot cover scenarios like this because they are restricted to essentially field names and types. Plus, they require specialist tools and organisational support to implement correctly all of which takes time.
We solved this to some extent (atleast for the dto conversion in the web service adapters) by creating loopback HttpMessageHandler derivatives and having them simply spit out the deserialised value of the DTO and exposing it the same way we did for the other in memory stores, so we can assert on the field values:
| namespace Domain.Tests.Unit.Stubs | |
| { | |
| internal class SubmissionServiceHttpHandlerStub : HttpMessageHandler | |
| { | |
| private Dictionary<string, Payload> _requestPayload; | |
| protected override async Task<HttpResponseMessage> SendAsync( | |
| HttpRequestMessage request, | |
| CancellationToken cancellationToken) | |
| { | |
| _payload = JsonConvert.DeserializeObject<Dictionary<string, | |
| Payload>>( | |
| await request.Content.ReadAsStringAsync()); | |
| // Assume that submission was successful, | |
| // construct the response payload | |
| var result = ConstructResponsePayload(_payload) | |
| return new HttpResponseMessage(HttpStatusCode.OK) | |
| { | |
| Content = new StringContent(JsonConvert.SerializeObject(result)) | |
| }; | |
| } | |
| internal Payload PayloadDto( | |
| string key) => | |
| _payload[key].FirstOrDefault(); | |
| } | |
| } |
The assertion in tests would then be (a bit verbose but still):
| [Fact] | |
| public async Task ShouldSubmitCorrectPayload() | |
| { | |
| // ... Do all the set up required i.e. stubs, domain objects | |
| // with pre-cooked data neccesary to execute the behaviour. | |
| // Build the service/adapter object with this mock HttpMessageHandler | |
| var loopbackHttpHandler = new SubmissionServiceHttpHandlerStub(); | |
| var submitter = new SubmissionService( | |
| new HttpClient(loopbackHttpHandler) | |
| { | |
| BaseAddress = new Uri("http://foo.bar") | |
| }); | |
| var useCase = CreateUseCase(submitter); | |
| useCase.Execute(...); | |
| // verify that what will have been submitted to the external | |
| // service would have been the right data | |
| var payload = loopbackHttpHandler.PayloadDto("key"); | |
| payload.Field1.Should().Be("abc"); | |
| payload.Field2.Should().Be(10); | |
| // other assertions | |
| } |
The one problem we haven’t solved yet but we are hoping to, is having the DTO conversion logic in the database adapters go through the same gauntlet.
There is ofcourse the option of writing very fine grained tests just for the conversion logic and while its fine to start out that way, ultimately you want to test the behaviour of the application and with the tests that I described above, you get the coverage of the entire use case not including the dto conversion. Tests should reach out as close to the edges of the system as possible but no closer.
Integration Testing: This kind of testing splits opinions because it is expensive to set up and run and can tend to be flaky if subjected to the nuances of the technology and/or underying data (in case of databases). However, I feel that plain ol’ hitting F5 with necessary services running locally, executing the use cases and seeing what comes out the pipe, is the next best thing and is the least we should always do. We used the following ways to do this (none that can be easily integrated with our CI/CD pipeline however…for now):
- Mock local infrastructure: Because our services are hosted in AWS and rely on SQS queues and MySql databases, we found this brilliant mocking framework for most AWS services (called Localstack) which you can spin-up locally and create things like SQS queues, SNS topics, DynamoDB tables etc. exposed on well known localhost ports. Using this has been very helpful for us when we want to run and debug the use cases that get their input from SQS queues for example.
Another piece of local infrastructure we have to good effect was Docker, instead of installing MySql locally and setting it up, we simply pulled the docker image for it and applied migrations using Flyway (which itself is available as a Docker image). In order to reduce manual bootstrapping effort, we stuck all these commands into adocker-compose.yamlfile. So all we needed to do was rundocker-compose upfrom a command line and magically all our local infrastructure was set up. We published some test messages to the local queues and we were off! - Test Adapters: Because we followed Ports and Adapters architecture for the application, we also created stub adapters for use during this local “integration” testing when we wanted predictable results in a controlled environment. They look indistinguishable from the stubs you create when you write tests, except, these live in the same assembly as the actual adapter and can easily be bootstrapped conditionally.This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
namespace PurchaseOrderAdapter { public class AlwaysCancelPurchaseOrderLineSuccessfully : ICancelPurchaseOrderLine { public Task<Result> Cancel( PurchaseOrderLine purchaseOrderLine) { // simulate success while calling an "external" service return Task.FromResult(Success( purchaseOrderLine)); } } }
Then we bootstrapped this test adapter in for local development work like so:This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characterspublic void RegisterServices() { // while running the service locally, mock external call // so it always succeeds (as long as it // itself is not the subject of the test) var isDevelopmentEnvironment = DetermineCurrentEnvironment(); if (isDevelopmentEnvironment) webserviceContainer.Register<ICancelPurchaseOrderLine, AlwaysCancelPurchaseOrderLineSuccessfully>(); else // otherwise use the actual live web service adapter webserviceContainer.Register<ICancelPurchaseOrderLine, RealPurchaseOrderService>(); }
This can be specially useful for the adapters that talk to external services that you don’t control but you don’t want your testing to be jeopardised by that service going down at the wrong time. For e.g we also test with dummy data which wouldn’t exist in the central database so we created a test adapter that will always give us the result we want and that way we can stand up all required services and applications with stubbed dependencies where appropriate and hit the proverbial button to see what’s the outcome end to end. We also used this strategy to good effect when testing the user handling of suggestions and seeing if the e-mails get sent.
Lesson 7: Write behavioural tests using appropriate stubs (both at unit and integration testing level). Get test coverage as close to the entry and exit points in your architecture as possible but no closer. Hit F5 and test the integration locally…at the very least!
This system is still in active development so we are constantly evolving it and learning more about it but hopefully, there have been some insights in these 7 lessons. Feel free to share your thoughts in comments (if you managed to reach this far…that is, in which case thanks for sticking around 🙂 )

Hi,
Interesting read. I was wondering how your application package/module structure looks like. More specifically where do you put the event handlers in het ports and adapters architecture?
Thanks
We have a separation between event handlers (which are domain concerns and live in the domain project) and a message “pump” (that listens on queues for these messages and is a part of a messaging adapter project). These messages are then converted into events in the domain and dispatched to event handlers for actual processing. You can see this delineation in the hexagon diagram in the post.
Sorry can’t seem to be able to attach screenshots in comments! I will add one to the post later.
Hi Aman – I have been recently introduced to DDD and Hexagonal Architecture. This blog post was incredible as it has concrete details which are difficult to find. Thank you for sharing this information it has helped me tremendously.
I have 2 questions around Dead Letter Queues and Optimistic Locking.
My team is implementing a Dead Letter Queue in Hexagonal Architecture. My plan is to create a DLQ adapter, but that would mean my driving adapter (a Kafka consumer) would depend on another adapter (the DLQ driven adapter) when there was a non-consumable message. The Kafka adapter would call the DLQ adapter to dead letter the message. My understanding is that coupling adapters is not good design choice to keep the code easy to change and easy to test.
My other concern is when a message is consumable from an adapter perspective (e.g. valid JSON), but upon further domain validation it is not a valid message and needs to be dead lettered. But we are already in the domain, so we’ve lost the raw Kafka event as it has been mapped to a domain object.
How did you implement the DLQ in Hexagonal Architecture to keep the adapters decoupled and how did you dead letter on domain validation failure?
My other question is around Optimistic Locking. I didn’t know this existed and was struggling with a data consistency issue without the use of database level locks, and I read your blog at exactly the right time to help me find a better solution for my situation.
My issue is how to handle the optimistic lock version. I need to be able to save the optimistic lock version between calls to the database. I call the database adapter, map to a domain object, execute some behavior, map back to a database object, and save it to the database. The best solution I see is introducing a version attribute to the domain object. But this feels wrong as it is an implementation detail of database consistency and not part of the domain. But I don’t know how else to have pass the version back to the database.
Should I add the OL version to the domain object, or is there another way to handle this?
Hey RL, thanks for your questions and glad my posts helped. I find it very useful and helpful when I read people’s real life software engineering experiences, so I figured I will return the favour and help the community to whatever little extent I can. 🙏
Now to your questions:
Have a look at this ports and adapters basics article I wrote a while ago as well that helps clarify the meaning of ports and adapters. Then, you could throw exceptions (or use result codes if you are so inclined) in the domain code to signal back to the messaging adapter that the consumption failed and the adapter can then appropriately dead letter the message (assuming you will be making sure to handle dequeue counts, message ordering etc). In my case, we used AWS SQS which automatically dead letters messages based on dequeue counts so we didn’t have to write custom code to handle DLQ-ing.
On the other hand, if the versioning were purely handled in the data layer code then a migration to a new database might still require rewriting and testing the version handling code as well, but in the grand scheme of migration, that’s a small cost to pay. You also have to ask yourself, how likely is it that you will change the database willy-nilly? I would imagine that the choice of a database is a deliberate and strategic one based on the problems you are solving, so its unlikely you will miss the mark by that much so as to warrant that migration. Even so, migrations do happen.
On the yet another hand, putting version in domain objects makes the concurrency aspect explicit so we don’t fool ourselves into thinking that concurrency doesn’t matter (in some cases it doesn’t, but I am going to assume otherwise here). It also helps with tests to some extent. However, in a modestly concurrent system handling the version increments in the domain code could result in concurrency conflicts more frequently than if the data layer were handling it simply because of staleness of data in-memory and race conditions. This was less of a problem for our use case because it was mostly message driven so retries will automatically resolve conflicts, but this could be annoying if its a user facing flow.
There is another more pragmatic approach that I have been using lately, i.e., you can expose version into the domain object but as read only. Upon retrieval of the object from the database, you can send this retrieved version back to the client/user and when they make a change, they will send this same version back to your API (you can make it explicit in the contract of the interface that you expect the current version number). You then pass this version number to your data layer that does the actual increment if the stored and provided versions are the same, otherwise, throws exception. This approach is still susceptible to domain model coupled to the database way of defining versions but at least, the knowledge of how version needs to be updated and when, lives in the data layer.
To be honest, in my view, its not as valuable to try and keep things 100% pure as tutorials will have you believe, that purity could also come at the cost of increased complexity (e.g. magic frameworks and libraries). You do the best you can to solve the problem in a reliable way, do some experiments with approaches to get concrete evidence, make informed trade-offs and change your designs when they no longer are sufficient. To me that’s more useful because it allows you to balance speed of delivery and reliability.
Anyway, I hope all this rambling makes some sense to you. I would be keen to know how things pan out for you, so feel free to drop another comment. Thanks once again.