
Recently a planned AWS Aurora database failover/master reboot caused database connection failures in one of our services which caused me to delve deeper into how MySql driver manages connections under the hood (still only scratched the surface though). I am documenting this, mostly for me when I have forgotten all about it in the future, but for anyone else who might be interested as well.
MySql Connection Management Under the Hood
Before I describe the problem we had, let’s see how the MySql client creates a connection to the database. Most basic form of connection creation code looks like this:
| using (var connection = new MySqlConnection( | |
| "Server=mydatabase.com;Port=3306;Database=MyDB;Uid=user;Ssl Mode=Required;Pwd=pass123;Pooling=False;")) | |
| { | |
| connection.Open(); | |
| // do things with connection for e.g. CRUD etc | |
| } |
With No Connection Pooling
The MySqlConnection class creates a new NativeDriver instance which will eventually be used as a proxy to talk to the database.
This NativeDriver then opens a new database connection by:
- Doing DNS lookup on the database host name to resolve its IP address. and then,
- Creating a TCP socket connection to this IP address. This socket connection is wrapped in a
NetworkStreaminstance which forms the underlying stream for the driver to talk over.
If either of these steps fail for some reason (for e.g. DNS lookup failure or connection timing out etc) and the base stream couldn’t be initialised, a MySqlException is thrown with error number 1042: Unable to connect to any of the specified MySQL hosts.
If the connection is established successfully, then this driver is used on all subsequent attempts to talk to the database.
This underlying network connection is closed when the instance of MySqlConnection is disposed.
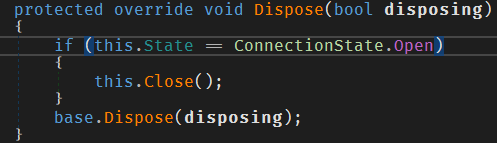
This helps prevent resource leaks if you as a developer forget to call connection.Close() yourself.
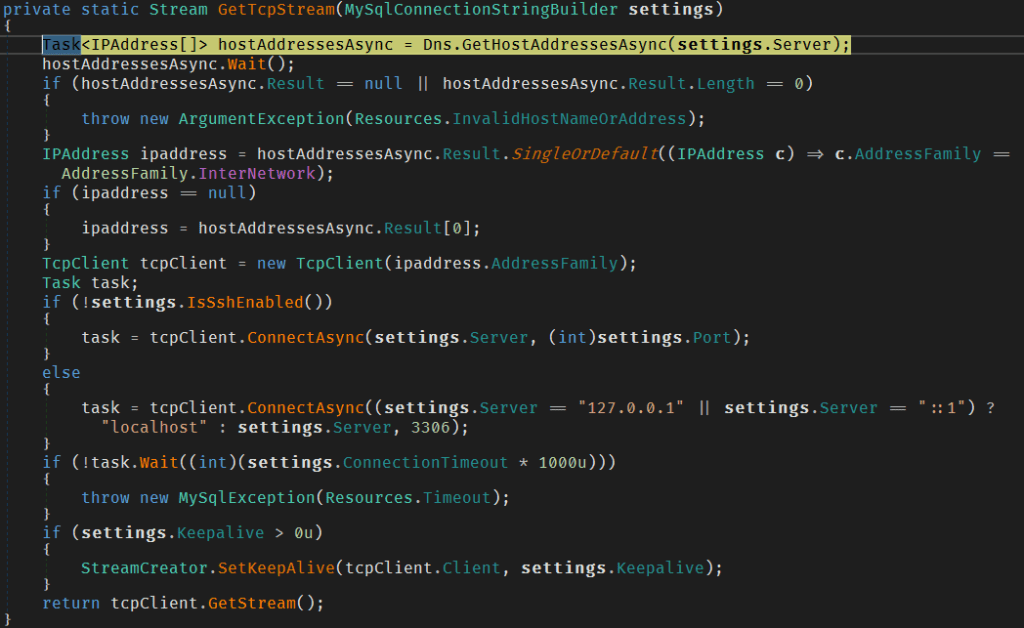
But there is a fundamental problem with the above approach, we are creating a new socket connection every time we need to talk to the database. Its completely possible to have thousands of queries and commands running in an average sized enterprise application. Each one of them allocating memory and threads to deal with the underlying socket connection and then taking it all down.
Not to mention, we are going to be doing DNS lookups (as shown in the screenshot of the StreamCreator class below) with every new connection and all of this will severely limit the app’s throughput and responsiveness and is wasteful of resources.
With Connection Pooling Enabled
Connection pooling addresses the problem of inefficient resource usage by creating a bunch of connections up-front with the very first call to connection.Open() and then simply reusing one of these available connections in the pool, for future requests.
This means that I can now call Open/Close methods multiple times without risking a new socket connection every time. So how does this work under the hood?
Connection pooling is enabled by default unless you explicitly disable it by setting the Pooling to False in the connection string (the properties highlighted in bold, determine the connection management strategies in the driver).
Server=<>;Port=3306;Database=MyDb;Uid=<>;Ssl Mode=Required;Pwd=<>;Pooling=True;ConnectionLifetime=<>;MinimumPoolSize=<>;MaximumPoolSize=<>
First, the number of connections in the pool can be configured via the connection string by specifying the MinimumPoolSize and MaximumPoolSize . The default for min is zero (i.e. only one connection will be created during the Open() call) and max is 100 (cannot have more than a 100 connections to the database).
A connection pool essentially is comprised of 2 lists: idle pool and in-use pool. The idle pool stores the Driver instances that are not actively being used at the moment (but still holding on to the resources) and the in-use pool stores Driver instances that are currently being used.
If you’ve specified a non-zero MinimumPoolSize, then that many connections will be opened up-front, put in the idle connection pool and maintained for the life time of the application at no point falling below the minimum. Otherwise a single connection will ping-pong between being idle and active.
A pool manager maintains a pool per connection string i.e. you can have connections to multiple MySql databases in the same application and all of them will benefit from pooling. When a connection is opened, a connection from the idle pool is checked-out if there are any available, otherwise, a new connection is established, added to the in-use pool and returned to the application to use.

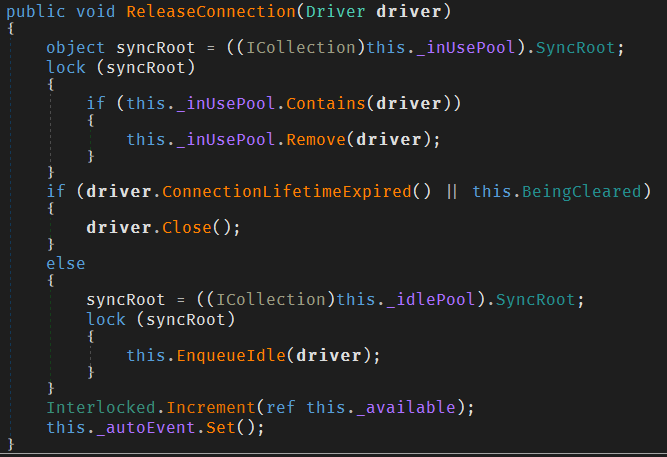
When the application is done with the connection, this connection is removed from the in-use pool (if it was still being used) and if it’s not expired already (as determined by the ConnectionLifetime property in the connection string), then its simply returned back to the idle pool, otherwise, the underlying socket connection is closed and resources freed-up (as shown in the screenshot).
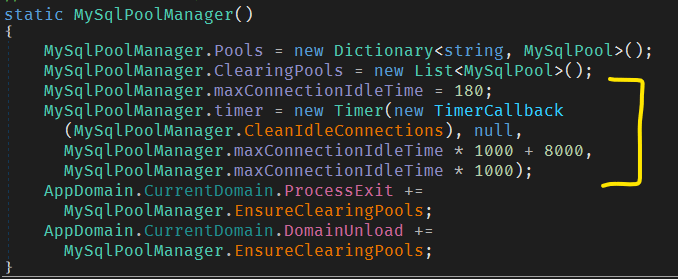
Each connection (or more accurately each Driver instance) can be given a ConnectionLifetime i.e. the amount of time in seconds for which its allowed to live in the idle pool, since its first creation, before being cleared off on a schedule by the pool. This schedule is set to 3 minutes and cannot be altered by the developer from the outside.


This is especially useful to cater for database failover scenarios where the host name is pointed from the original master instance to a new master instance resulting in a different database IP address. If these connections stayed indefinitely in the idle pool and re-used, they will have been trying to connect to an IP address that is no longer available or is not the master anymore. This will cause random failures in the application and depending on how the application is designed, could even result in data loss.
However, picking too low of a value for the ConnectionLifetime can completely negate the advantages of pooling as you would be creating new socket connections way too frequently.
Database Failover Scenario (or What Went Wrong for Us)
Our application uses connection pooling with indefinite connection life time. Last week we deployed a change to our AWS database stack which required the Aurora database instances to be rebooted and one of the read replicas to be promoted to a master and the old master to become read only.
As soon as this change was deployed, our application started reporting the following error:
Unable to connect to any of the specified MySQL hosts
This is to be expected during a failover/reboot but after a while the errors changed to the below which was a lot more perplexing:
The MySQL server is running with the --read-only option so it cannot execute this statement
Apparently, what had happened was, due to pooling and the fact that the connections had an indefinite life, the pool never discarded the connection with the old IP address and kept using it even after the failover. That IP address now belonged to a read replica against which we were trying to do writes and this promptly failed with the second error.

The big learning for me here was that the Aurora clusters DO NOT behave like load balancers (at least not in our context) and the host name resolves to the IP address of the actual backend instance (reader or writer). This is why during a failover, without appropriate handling, you could be connecting to an instance that is no longer the master.
ELB host names by contrast resolve to the public IP addresses of the load balancers themselves rather than the private IP addresses of the backend EC2 instances. This is why stateless backend application servers hosted on EC2 instances (in an Auto Scaling Group) getting rebooted, doesn’t really impact your application at all since you only ever connect to the load balancer and the load balancer then finds a healthy instance to connect your app (unless the ELB itself is undergoing a DNS failover to a different region).
Since our application handles events from queues, any errors in the event handling loop will simply cause the messages to be moved to a Dead Letter Queue after 5 consecutive failed attempts to process it. In the absence of a viable DLQ management strategy, those messages i.e. writes are effectively lost.
Panic “Fix”
In order to recover from this and ensure we don’t lose any more writes, we temporarily disabled the message handling and redeployed the service. This act basically flushed the idle pool and recreated a new connection to the new master. We then re-enabled message handling to resume normal processing.
Proper Fix
The proper way for the application to have handled this scenario would have been – detecting that the old connection(s) are no longer pointing to the master therefore drop them and re-create new connections, this time to the new master (thanks to the fresh DNS lookup).
It turns out the MySqlPool has some kind of liveness check built into it:
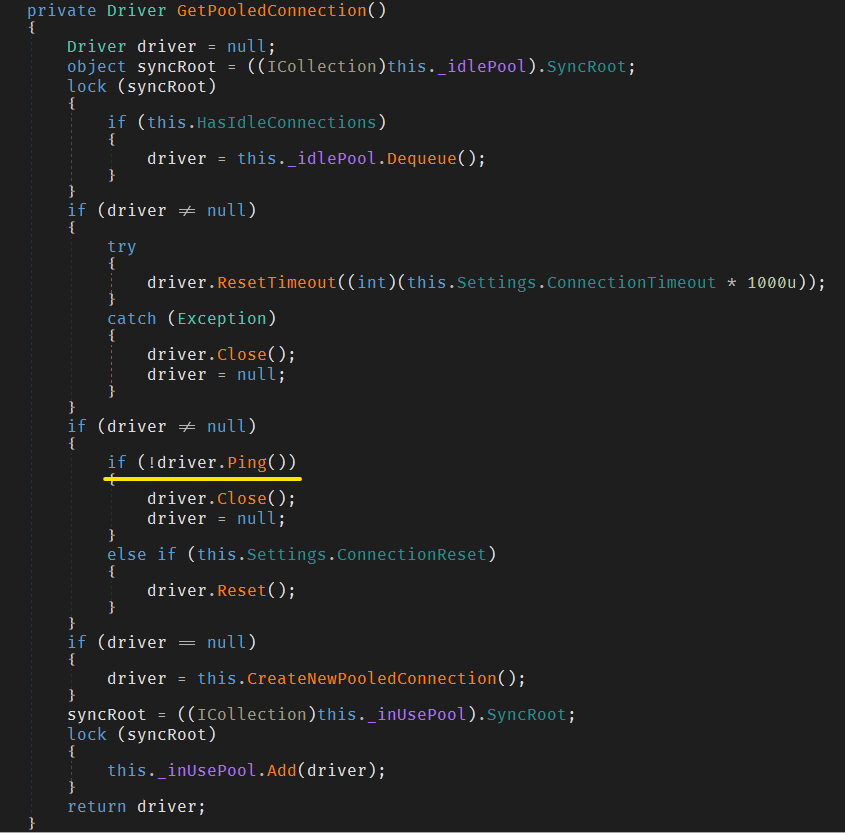
This live-ness check tells the driver if the connection to the server is still valid. The problem is that this check doesn’t see if the connected database is the master or not (neither should it), which means this check will report OK even if it was connected to the read replica.
So what else can be done to make the application more resilient to database failovers like this?
The hint lies in AWS’ own documentation on Aurora failover (apart from describing what happens during one):

If I could establish a new connection following a failover, then I should be able to have the app auto-recover.
The key constraint behind retries being that the error should be a retriable one. For e.g. primary key violations are not retriable because the problem is not a transient infrastructure problem but a data issue that needs to be resolved separately. So I needed to identify what error codes and HRESULTs will constitute a failover and create a Polly retry policy to handle exceptions carrying those specific error codes.
To test this is in a meaningful way$$, I set up an Aurora MySql cluster on AWS with 1 writer and 2 read replicas and wrote a C# program to insert a bunch of records to it in a loop. As the inserts were happening, I kicked off a manual failover on the database which caused the application to fail with a MySqlException. I made a note of the exception number and the accompanying HRESULT.
MySql client package for .NET Core offers a useful enumeration called MySqlErrorCodes that…well…enumerates all error codes. The one that I needed to set up the retry policy were these two:
MySqlErrorCode.UnableToConnectToHost and MySqlErrorCode.OptionPreventsStatement (the --read-only error has this number)
I also noticed that on some occassions, the first exception had the number of zero and HRESULT of -2147467259. This exception was raised when the command execution failed fatally. Number of zero typically means host connection issues so I also included this combo to my failover condition.
| public static class MySqlExceptionExtensions | |
| { | |
| public static bool IsFailoverException(this MySqlException mySqlException) | |
| { | |
| return mySqlException.Number == (int)MySqlErrorCode.UnableToConnectToHost || | |
| mySqlException.Number == (int)MySqlErrorCode.OptionPreventsStatement || | |
| (mySqlException.Number == 0 && mySqlException.HResult == -2147467259); | |
| // Fatal error reading from the stream, usually Number being 0 means host connection issues | |
| } | |
| } |
As mentioned before, ConnectionLifetime could be configured in the connection string to ensure that connections don’t stay in the pool for too long. I have found the value of 1 minute to be acceptable in this case (this will ofcourse depend on the application type i.e. how many database interactions your application does at any given time and how long it takes databases to failover in this case around 30 seconds to 1 minute). After this time, the connection will be removed from the pool and a brand new one will be created.
I created my retry policy accordingly to cover the whole 60 second window i.e. by doing 5 retries and waiting for (retryAttemptNumber * 5) seconds in between each retry. This will give a smooth arithmetic progression of 5s, 10s, 15s, 20s, 25s with the total being around 75 seconds – long enough for the connections to self-purge.
| var policies = Policy | |
| .Handle<MySqlException>(x => x.IsFailoverException()) | |
| .WaitAndRetry(5, | |
| retry => TimeSpan.FromSeconds(retry * 5), | |
| (a, b) => | |
| { | |
| var mySqlEx = a as MySqlException; | |
| Log.Logger.Warning( | |
| "Failed with: {@error}. Retrying in {x} seconds...", | |
| new | |
| { | |
| Msg = mySqlEx.Message, | |
| Number = mySqlEx.Number, | |
| HR = mySqlEx.HResult | |
| }, | |
| b.TotalSeconds); | |
| }); |
Alternatively, I could leave the ConnectionLifetime on its default value of 0 (i.e. indefinite life) but handle the MySqlException myself initially and if the exception is a failover exception, then I can explicitly clear the connection pool. This exception would be then re-thrown so Polly can handle it and apply retries on it.
| policies.Execute(() => | |
| { | |
| using (var conn = new MySqlConnection(ConnectionString)) | |
| { | |
| try | |
| { | |
| conn.Open(); | |
| conn.Insert(new Record { Id = i + 1, Name = $"Aman {i + 1}" }); | |
| Log.Logger.Information( | |
| "Inserted row with id {id} successfully!", | |
| i + 1); | |
| } | |
| catch (MySqlException mysqlEx) | |
| { | |
| if (mysqlEx.IsFailoverException()) | |
| { | |
| Log.Logger.Warning( | |
| "Clearing current connection pool because an exception {@exception} occurred", | |
| new | |
| { | |
| Msg = mysqlEx.Message, | |
| Number = mysqlEx.Number, | |
| HR = mysqlEx.HResult | |
| }); | |
| // for this call to do anything, the idle pool should have non-zero connections | |
| // which it will after the connection is disposed. This increases the likelihood | |
| // of retries succeeding. | |
| MySqlConnection.ClearPool(conn); | |
| } | |
| throw mysqlEx; | |
| } | |
| } | |
| }); |
Both approaches seem to work, however, I have found the manual pool clearing approach to be more reliable since its increases the likelihood of the connections being cleared.
Here’s the overall code with retry policy (quick and dirty):
| private static string ConnectionString = | |
| "Server=db.com;Port=3306;Database=MyDB;Uid=user;Ssl Mode=Required;Pwd=bla;Pooling=True;ConnectionLifeTime=60"; | |
| private static void WriteResiliently() | |
| { | |
| var policies = Policy | |
| .Handle<MySqlException>(x => x.IsFailoverException()) | |
| .WaitAndRetry(5, | |
| retry => TimeSpan.FromSeconds(retry * 5), | |
| (a, b) => | |
| { | |
| var mySqlEx = a as MySqlException; | |
| Log.Logger.Warning( | |
| "Failed with: {@error}. Retrying in {x} seconds...", | |
| new | |
| { | |
| Msg = mySqlEx.Message, | |
| Number = mySqlEx.Number, | |
| HR = mySqlEx.HResult | |
| }, | |
| b.TotalSeconds); | |
| }); | |
| for (var i = 0; i < 10_000; i++) | |
| { | |
| policies.Execute(() => | |
| { | |
| try | |
| { | |
| using (var conn = new MySqlConnection(ConnectionString)) | |
| { | |
| conn.Open(); | |
| conn.Insert(new Record { Id = i + 1, Name = $"Aman {i + 1}" }); | |
| Log.Logger.Information( | |
| "Inserted row with id {id} successfully!", | |
| i + 1); | |
| } | |
| } | |
| catch (MySqlException mysqlEx) | |
| { | |
| if (mysqlEx.IsFailoverException()) | |
| { | |
| Log.Logger.Warning( | |
| "Clearing current connection pool because an exception {@exception} occurred", | |
| new | |
| { | |
| Msg = mysqlEx.Message, | |
| Number = mysqlEx.Number, | |
| HR = mysqlEx.HResult | |
| }); | |
| // for this call to do anything, the idle pool should have non-zero connections | |
| // which it will after the connection is disposed. This increases the likelihood | |
| // of retries succeeding. | |
| MySqlConnection.ClearPool(conn); | |
| } | |
| throw mysqlEx; | |
| } | |
| }); | |
| Thread.Sleep(100); | |
| } | |
| } | |
| public static class MySqlExceptionExtensions | |
| { | |
| public static bool IsFailoverException(this MySqlException mySqlException) | |
| { | |
| return mySqlException.Number == (int)MySqlErrorCode.UnableToConnectToHost || | |
| mySqlException.Number == (int)MySqlErrorCode.OptionPreventsStatement || | |
| (mySqlException.Number == 0 && mySqlException.HResult == -2147467259); | |
| // Fatal error reading from the stream, usually Number being 0 means host connection issues | |
| } | |
| } |
I created a little screen gif of this policy in action:
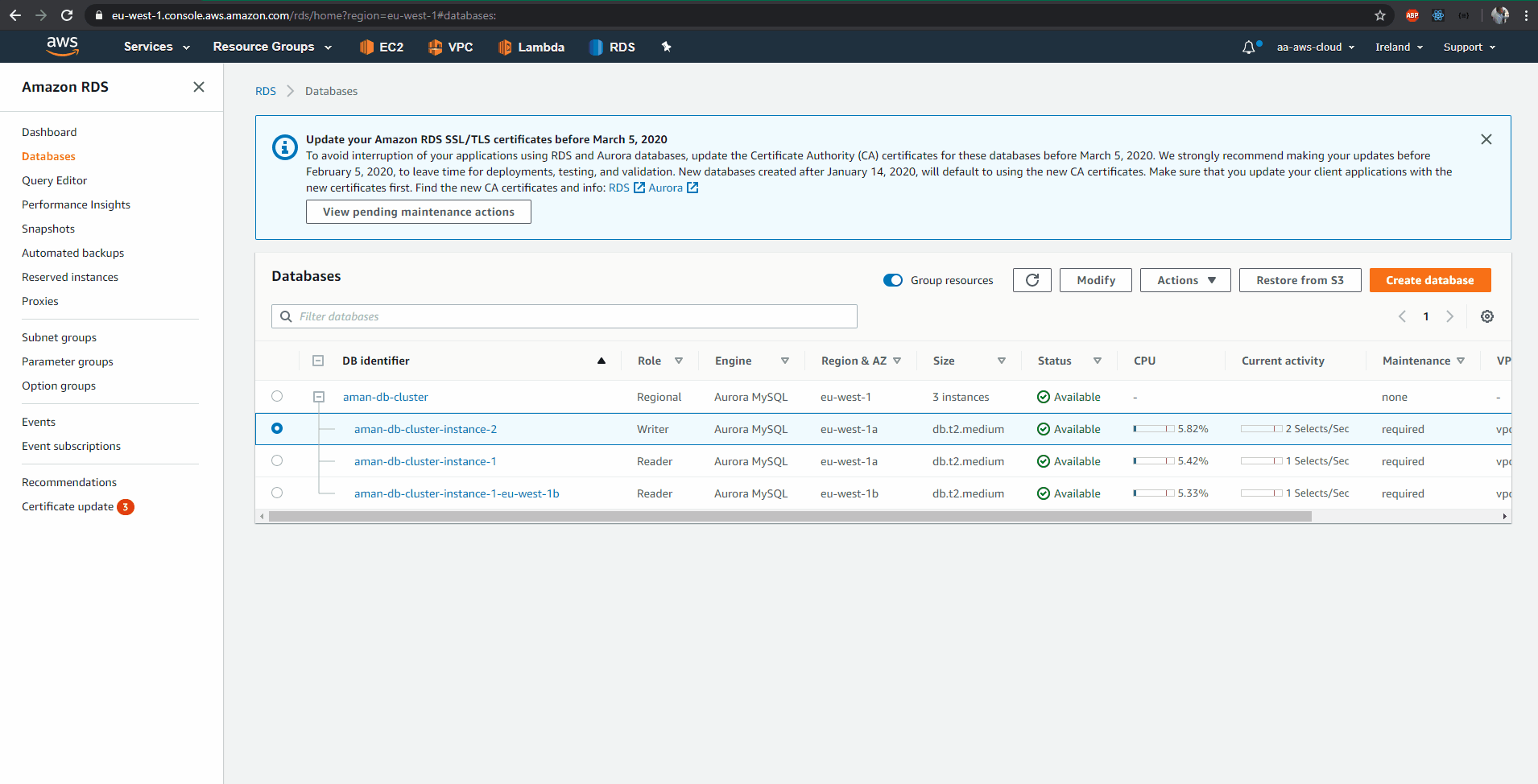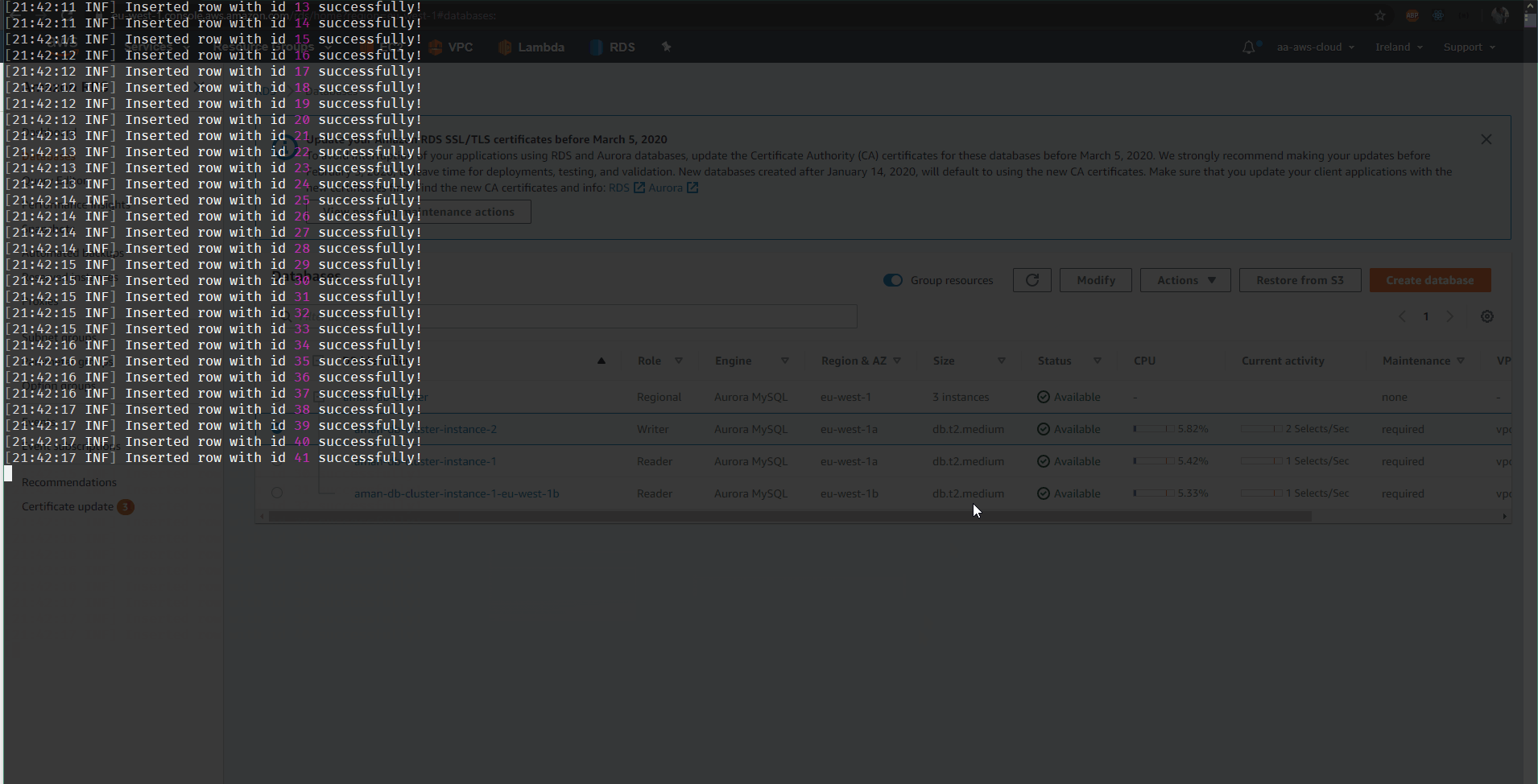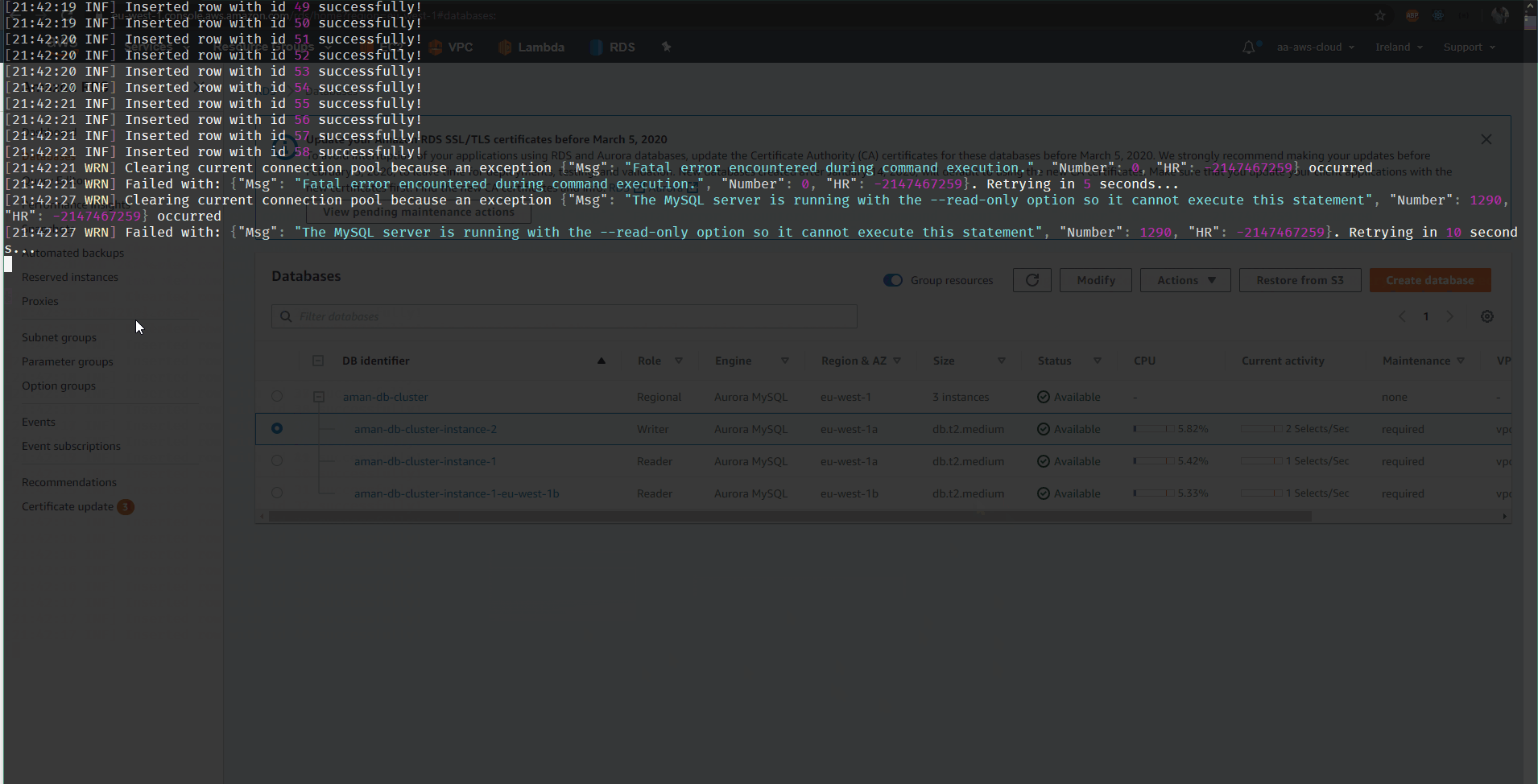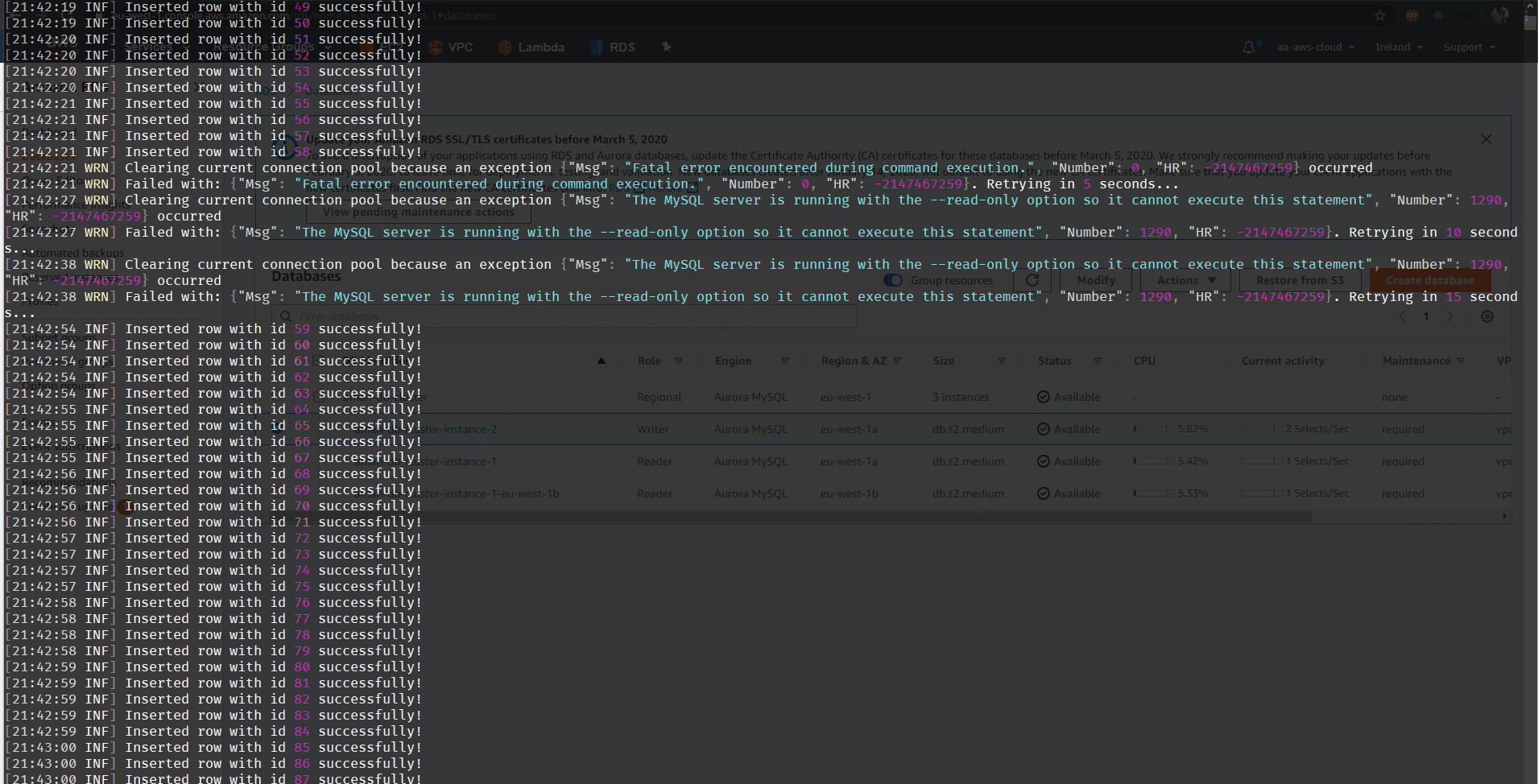
For event driven scenarios like ours, you still need to handle and re-queue DLQ messages, if for some reason failover lasts longer than the total retry duration. In this scenario, in addition to retries, a circuit breaker will also help reduce traffic to the database server and allow it time to recover and fail fast. Then eventually as the server recovers you can re-queue the messages to be processed again!
The code for this has been tidied up into class library and available on GitHub and an experimental Nuget package is also available for download.
$$ You don’t need to have a RDS cluster running on AWS, you could just use a Dockerised MySql image and do this all locally as well. A failover will then just be stopping and re-starting a container.
EDIT (28-Jan-2020): Since writing this post, I have come across this brilliant handbook on Aurora connection handling that basically touches on some of the points that I have mentioned in post. It also expects the database drivers used by programming languages to be smart enough to be able to deal with failovers and reboots and quotes the official MariaDB driver as one such package. This one seems to have in built behaviour to deal with Aurora failovers, similar to a retry policy I have created in this post (albeit MariaDB’s might be more clever).
One final bit of revelation is the RDS Proxy service that sits between your application and the RDS database very much like a load balancer and allows you to offload all the nitty-gritty of connection management from your application. Your application always connects to the IP address of the proxy and the proxy manages the underlying connection to the RDS instances. This way your are effectively “immune” from failover problems. I am yet to try it out with C# apps, perhaps that will be another post.
