
I recently migrated my ASP.NET Core 2.2 app to ASP.NET Core 3.1 so I thought I will document some experiences and learnings from this exercise.
The ASP.NET Core 2.2 app runs as an Azure App Service (Windows) on Azure on a D1 Shared app service plan backed by a Azure SQL relational database. I have a CI/CD pipeline set up on Azure DevOps that uses Cake script to build, test and publish the artifacts which are then deployed to Azure by the inbuilt Azure Web App task.
Since the upgrade from .NET Core 2.2 to 3.1 is somewhat of a breaking change with a few things around bootstrapping being different, I chose to do this migration in a crude blue-green manner as depicted in this diagram:

Because I wanted to keep the current version in production running with no impact (the green block in the diagram above) and test the upgrade in isolation, I decided to create a separate but identical App Service stack using Azure Resource Manager templates. My plan was to fork my main repo, make the upgrade on it and then deploy the changes to this testing environment from my fork (the blue block in the diagram above). This way master stays clean and unaffected until I am ready to switch over.
Microsoft have outlined the changes necessary for migrating the solution and projects in this article so that part is relatively easier. I then upgraded all 2.x Microsoft.* packages to their 3.x equivalent and re-ran the app locally to test it and this is where things got interesting! All the operations that saved/updated data in the database, started failing with this exception:
Microsoft.EntityFrameworkCore.DbUpdateConcurrencyException: 'Database operation expected to affect 1 row(s) but actually affected 0 row(s). Data may have been modified or deleted since entities were loaded. See http://go.microsoft.com/fwlink/?LinkId=527962 for information on understanding and handling optimistic concurrency exceptions.'
The app uses Entity Framework Core 3.0 for data persistance and between 2.x and 3.x the way entities are added/updated has changed. Let me show by example, say we have a simple model:
| public class Blog | |
| { | |
| private readonly List<Post> posts = new List<Post>(); | |
| public string Name { get; } | |
| public Guid Id { get; } | |
| public IReadOnlyCollection<Post> Posts => posts.AsReadOnly(); | |
| private Blog() | |
| { | |
| } | |
| public Blog(string name) | |
| { | |
| Name = name; | |
| Id = Guid.NewGuid(); | |
| } | |
| public void CreatePost(string title, string content) | |
| { | |
| this.posts.Add(new Post(title, content)); | |
| } | |
| public void RemovePost(Guid postId) | |
| { | |
| var postToRemove = posts.FirstOrDefault(x => x.Id == postId); | |
| if (postToRemove != null) | |
| { | |
| posts.Remove(postToRemove); | |
| } | |
| } | |
| } | |
| public class Post | |
| { | |
| public string Title { get; } | |
| public string Content { get; } | |
| public Guid Id { get; } | |
| private Post() | |
| { | |
| } | |
| public Post(string title, string content) | |
| { | |
| Id = Guid.NewGuid(); | |
| Title = title; | |
| Content = content; | |
| } | |
| } |
And we have persistance code that looks like this:
| private static void Main(string[] args) | |
| { | |
| DbContextOptionsBuilder<MyContext> builder = new DbContextOptionsBuilder<MyContext>(); | |
| builder.UseSqlServer("<connection string>"); | |
| Guid blogId; | |
| Guid postIdToRemove; | |
| // Let's create the Aggregate root first i.e. Blog | |
| using(var ctx = new MyContext(builder.Options)) | |
| { | |
| var blog = new Blog("Aman'sThoughts.com"); | |
| ctx.Blogs.Add(blog); | |
| ctx.SaveChanges(); | |
| blogId = blog.Id; | |
| } | |
| // Now let's publish some posts in the blog | |
| using (var ctx = new MyContext(builder.Options)) | |
| { | |
| var blog = ctx.Blogs.Where(x => x.Id == blogId).Include(x => x.Posts).FirstOrDefault(); | |
| blog.CreatePost("Migrating from EF Core 2. to EF Core 3.0", "Its a bit broken!"); | |
| blog.CreatePost("Migrating from .NET Core 2.2 to NET Core 3.1", "Went kinda ok!"); | |
| ctx.SaveChanges(); // <--- this is where it blows up! | |
| } | |
| } |
And I configure my Entity Framework model like so (using the Fluent API):
| protected override void OnModelCreating(ModelBuilder modelBuilder) | |
| { | |
| modelBuilder.Entity<Blog>().Property(x => x.Id); | |
| modelBuilder.Entity<Blog>().HasKey(x => x.Id); | |
| modelBuilder.Entity<Blog>().HasMany(x=>x.Posts).WithOne().IsRequired(); | |
| modelBuilder.Entity<Blog>().Property(x => x.Name); | |
| modelBuilder.Entity<Post>().Property(x => x.Id); | |
| modelBuilder.Entity<Post>().HasKey(x => x.Id); | |
| modelBuilder.Entity<Post>().Property(x => x.Title); | |
| modelBuilder.Entity<Post>().Property(x => x.Content); | |
| base.OnModelCreating(modelBuilder); | |
| } |
In 2.x, this code will correctly add the new Post record to the Posts table but in 3.x, it will fail because it fools EF into thinking that any entity whose primary key is set must be being updated, so instead of issuing an INSERT it issues an UPDATE on an entity that doesn’t actually exist in the database. Hence the concurrency exception (which is a bit misleading but kinda makes sense because essentially concurrency failures also exhibit similar symptoms).
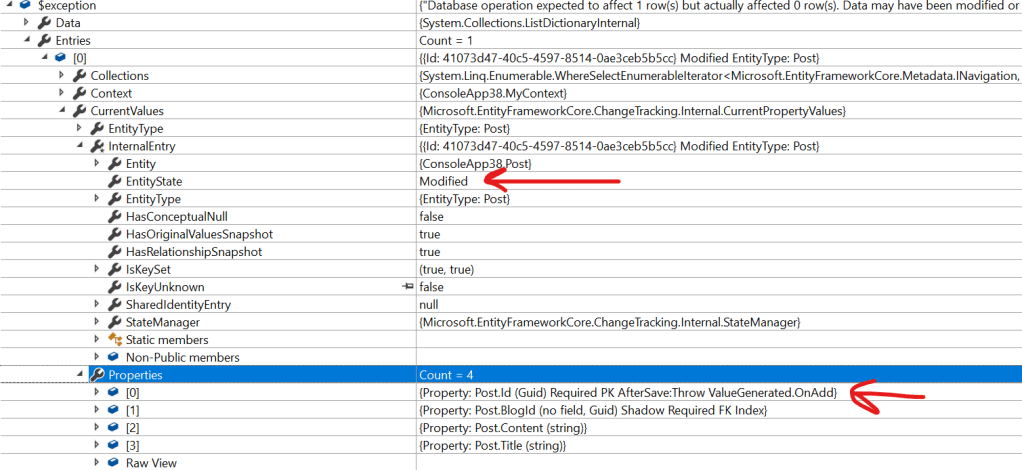
The problem lies in the default strategy for primary key generation in EF Core 3.0, when you configure your entity’s primary key property, the default beahviour of EF Core is to try and generate a value on add or update. If an entity has the value for the primary key set, EF treats it as an existing object and tries to update it, otherwise, it treats it as a new object and adds to the context.
So when I create my new domain entity and manually assign it an id value (like you should do to maintain separation between domain and persistance), EF Core is fooled into thinking that its an existing entity. The way to get around this, is to explicitly configure the primary key property to never be auto-generated from database by calling the ValueGeneratedNever() method on Fluent API as shown below (unless ofcourse you have good reason not to do so and rely on database generated ids):
| protected override void OnModelCreating(ModelBuilder modelBuilder) | |
| { | |
| modelBuilder.Entity<Blog>().Property(x => x.Id).ValueGeneratedNever(); | |
| modelBuilder.Entity<Blog>().HasKey(x => x.Id); | |
| modelBuilder.Entity<Blog>().HasMany(x=>x.Posts).WithOne().IsRequired(); | |
| modelBuilder.Entity<Blog>().Property(x => x.Name); | |
| modelBuilder.Entity<Post>().Property(x => x.Id).ValueGeneratedNever(); | |
| modelBuilder.Entity<Post>().HasKey(x => x.Id); | |
| modelBuilder.Entity<Post>().Property(x => x.Title); | |
| modelBuilder.Entity<Post>().Property(x => x.Content); | |
| base.OnModelCreating(modelBuilder); | |
| } |
This sorted out the problems with add/update/deletes.
Next, I deployed the upgrade from my fork to the testing environment that I had set up earlier. In order to do this, I had to set up a new CI/CD pipeline from my fork. I used the new YAML based Azure Pipelines model in Azure DevOps for this. There is a great VS Code extension that gives you syntax highlighting, intellisense etc that greatly helps in writing the templates from scratch.
I deployed the app to the testing environment where it was…well…tested. After that, I merged my fork back into the master, updated the database connection string in the CI/CD pipeline to point to the production database and redeployed the app this time from the main master to the production environment. To test it I navigated to it from the browser and got a 503 Service Unavailable! Errmm…what??
It seemed as though the dotnet process had failed to start for some reason! In order to rule out runtime not actually being available on Windows, I ran dotnet --info command on the App Service Console.
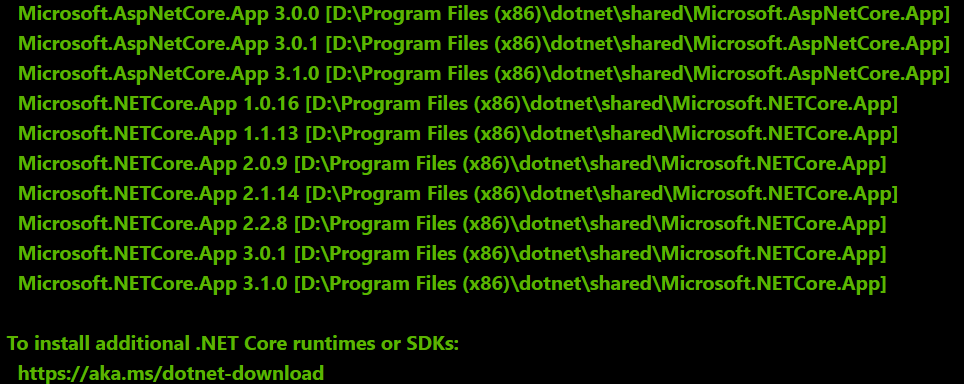
Surely enough the runtime is installed and supported on Windows even though the App Service UI would have you believe otherwise:

App Service logs and Application Insights didn’t reveal much so I decided to start the process manually via the same Console with the command dotnet .\myapp.dll (starting with .NET Core 3.1 a Framework Dependent Exe file is also produced when you publish binaries, you could also just invoke the exe directly). I waited for a while for this command to finish but after about 60 seconds, got greeted by this error on the console:

Even more perplexing because executing this same app locally, works! Although, beware that the default config only dumps Warning level logs and above to the console so at the first blush it might look as though the app has frozen but it hasn’t actually. Its just not logging Info level events! A quick netstat -abf to list running processes and ports they are listening on, can confirm this:
TCP 127.0.0.1:5000 LAPTOP-BA6565SB:0 LISTENING
[App.Web.exe]
TCP 127.0.0.1:5001 LAPTOP-BA6565SB:0 LISTENING
[App.Web.exe]
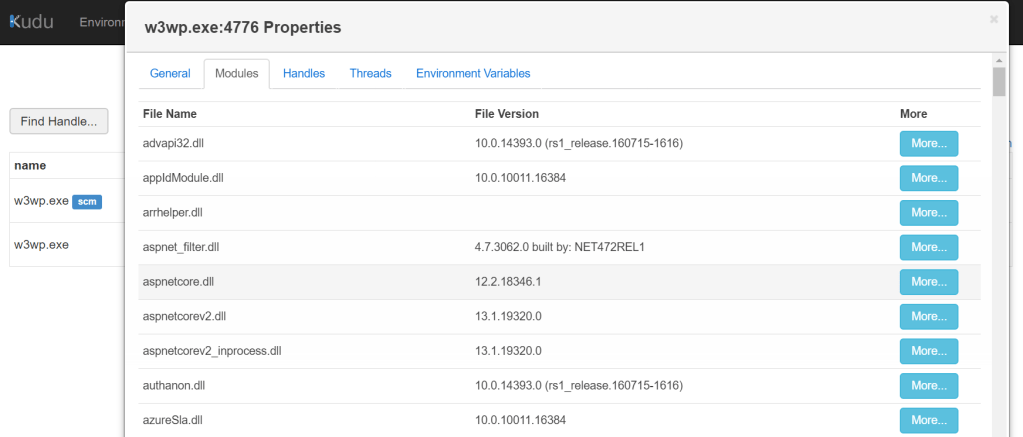
Unfortunately, you can’t run netstat on Azure App Service Console due to limited access for security reasons. What you can do to see what processes and modules are running is use the Kudu Tools option on App Service:
This portal gives you options like Process Explorer and mini-dumps from processes:
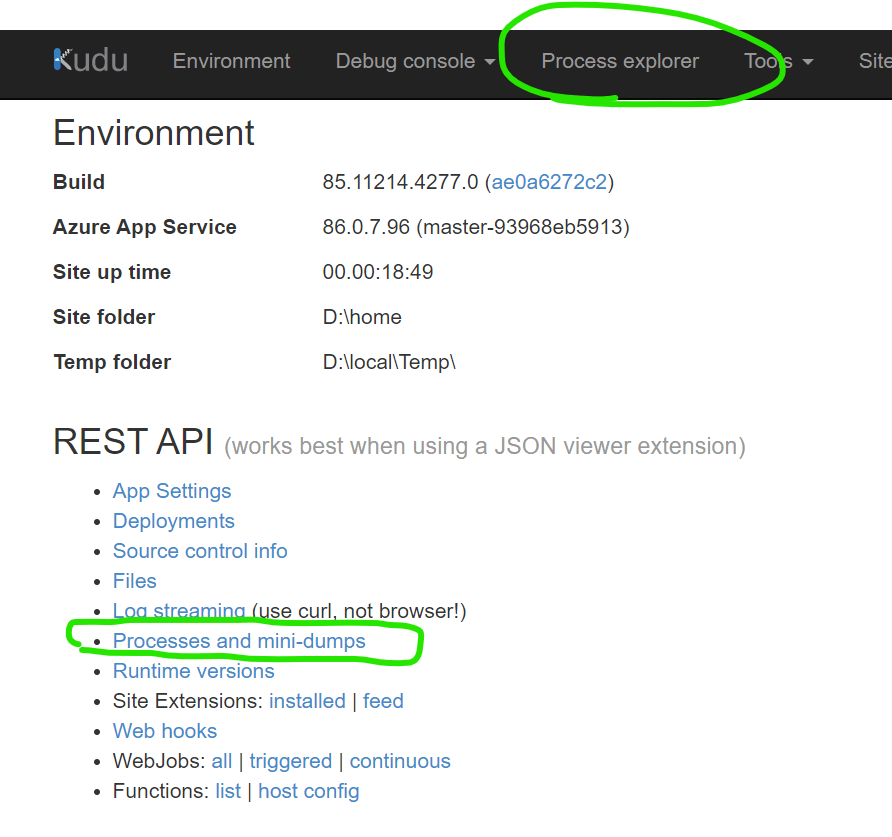
No sign of App.Web.dll in the Process Explorer! This explains the 503 but why hadn’t it loaded?
Then I happened upon this article which talked about various reasons why App Service apps could fail to start and the section that triggered a thought in my mind was this. Could it be that the bitness of the app and the host weren’t compatible? i.e. the app is somehow targetting a specific CPU architecture and the appropriate extension wasn’t available in the App Service?
I took a look at the app service configuration and found this to be quite suspect and for some reason it won’t let me change it either:
On a hunch, I installed the ASP.NET Core 3.1 x86 Runtime extension:
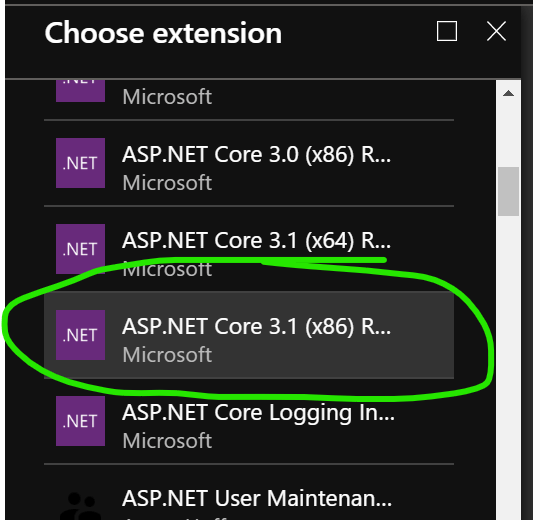
And lo and behold! this made the app load successfully! This was baffling since a .NET Core 3.1 app on an App Service should (and does) just work without requiring any additional configuration and extensions and I have since confirmed this by creating a test app and doing a deployment in a similar way. I don’t know what was so unique about my original attempt.
With the migration complete and the app health checks reporting healthy, I took down the testing environment and deleted the fork.
That was just about it, all in all the migration was smooth with some nice learnings along the way but certainly a great opportunity to revamp an old-ish stack and deployment pipeline.
