Seeing as micro-service architectures are all the rage these days, I decided to dip into it by building a petition application (see: Change.org or UK Parliament Petitions). It’s not a fully fledged production ready petition application like the two other platforms mentioned but I just wanted to take a crack at architecting & implementing it, also, I had been wanting to learn Angular so I decided to build this application’s front end using Angular.
I completely cooked up all the requirements as I went along (might sound fairly realistic though):
- The application should be able to handle unpredictable bursts of traffic easily especially during signing a very popular petition.
- Since the goal of the petition system is to make people’s voice heard, the responsiveness of the application is particularly important. The whole journey from finding about a petition to signing it should be as smooth as possible.
- The main activities in the system would be: a) Creating and launching a new petition b) Signing petitions. Both these activities are fairly independent of each other.
- A user must be logged on or registered, to be able to create or sign a petition. Viewing currently open petitions can be anonymous because I want people to be able to find out what petitions are running.
Once I jotted these requirements down, I built a simple domain model of the problem (the entities don’t have a complex relational structure which makes storage fairly easy). A petition can stay in one of 3 states: Created, Open or Closed during their lifetimes in that order.
- Created: a petitioner has only created i.e. saved a draft version of the petition and haven’t yet launched it out to the world. Perhaps they are doing some research etc.
- Open: once a petition is ready, the petitioner can launch it at which point it becomes open for wider public to see and respond to. This is the stage where people can sign it. Once the petition is open, it cannot be altered (hence a good candidate to be served from a low latency cache).
- Closed (Not implemented): this is penultimate stage of the petition where, after its run its cycle it may be forwarded to government representatives for action or generated a report out of. Since I have been mostly cooking the requirements I wasn’t sure how would I implement this so I left this part out, but I suppose there are possibilities around using Event Sourcing or Message Queuing for a lot of the back-end work.
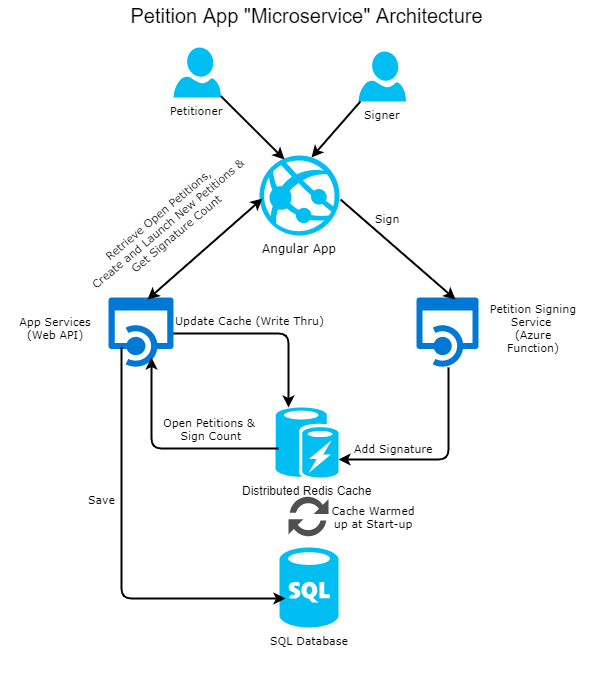
I started with the architecture design mostly from an infrastructure point of view, the usage of SOLID principles to actually build the application was a given. I didn’t want it to be a full monolith where all the data for the application lives in a single database and the same application process is responsible for petition management, authentication and signing. I knew the signing part can be separated from those parts of the system. I wanted to start thinking in “micro” terms right off the bat.
Although the petition management, authentication and registration facilities are still under a single process, they can be refactored out into their own micro-service in time. I just wanted to do the minimum work required to build a decently scalable architecture initially.
Since the number of signatures on a popular petition can reach into hundreds of thousands with unclear scaling requirements, on demand scaling was crucial for low latency. I didn’t want users to be stuck waiting for their signature requests to finish because the system is busy.
For this, I decided to use Azure’s serverless offering – Functions. I am sure there are better ways to implement microservices architecture, but I wanted to leverage existing technology as much as I can.
Of all the benefits of functions, the 3 most important (to me) are:
- They can quickly auto-scale based on the current load without any provisioning required from my side hence the term “serverless”.
- They can be triggered by events external to the function itself for e.g. a database record being created, HTTP request coming in, a message appearing in a queue etc.
- Functions run in their own process as a separate application so it’s decoupled from the main application such that even if the main application is misbehaving for some reason, its effect on signing service/function is very likely going to be low which is good from responsiveness perspective and is one of the key aspects of micro-services based architecture i.e. loose coupling and isolation.
NB: For this exercise I didn’t actually deploy my function on Azure, they just run locally.
There are time and memory limits imposed by Azure therefore functions shouldn’t be used for resource intensive operations for e.g. long running operations. WebJobs are a better fit for those kinds of jobs.
The other aspect of latency is data retrieval, disk backed stores like SQL Server are inherently slower than their memory backed counter parts like Redis, Memcached etc. If the time to load the open petitions list page during high traffic events reaches into many seconds, user experience will suffer drastically and people will start dropping out. It may not be critical to sign a petition that very moment and the users can always come back and retry but that’s something I wanted to avoid.
For this application, I went for a polyglot persistence model. I used:
- Redis cache as a primary storage solution for storing launched/open petitions and the signatures against those petitions (under separate keys). The in-memory persistence offers super low latencies and efficient data structures for storage and retrieval. This cache is pre-loaded with open petitions from the main SQL database at app startup once and only gets updated when a new petition is launched i.e. write thru caching.
- A SQL Server database to store the petitions for durability or analytics reasons. This database only serves petition details when a user clicks through into one. In time I am thinking of completely eliminating the need for retrieving anything from the SQL backend during normal application usage and only use it for back end reporting and cold storage purposes.
- Another SQL Server database to store the registered users and authenticate them against it at logon. This database is only used once per user session and most of the data is in one flat table so performance bottlenecks here are minimal.
Performance Testing Redis vs SQL Server (Win 10 x64, 32GB RAM, Core i5-7500 Quad Core, 1TB HDD):
In my preliminary performance tests where I compared the latencies between raw read and write operations between Redis and SQL Server, Redis very clearly outperformed SQL server by an order of magnitude.
Sequential writes of 100k petitions to Redis took: 5.6 seconds vs 249 seconds on SQL Server. In both cases, I used the default C# client library StackExchange.Redis for Redis and Entity Framework Core for SQL Server.
Concurrent writes of 100k petitions to Redis: 816 ms vs DNF (Did Not Finish) on SQL Server as my test rig crashed (probably because of issues with the Parallel.For loop).
On the read side, loading top 500 open petitions only once took 13.2 ms with no deserialisation and 24 ms with deserialisation vs 270 ms with SQL server with warm start and query plan possibly cached. The cold read from SQL Server actually took 2 seconds. That’s slower by a factor of 11 when compared to Redis even with the overhead of deserialisation and by a factor of 20 without deserialisation.
Concurrent reading of top 500 petitions with a total of 10,000 potential concurrent requests made took 17 seconds to finish on Redis with average throughput 588 RPS vs DNF on SQL Server. Same test with 100 concurrent requests took 152 ms on Redis (657 RPS) vs 2 seconds on SQL Server (50 RPS). Bottom-line: Use Redis for low latency reads and writes and keep SQL Server for highly consistent, relational and low throughput needs.
Storage Design:
For storing open petitions, I used the List data structure of Redis because doing a left or right push operation on a list is an O(1) operation i.e. near constant time and List is also suitable for implementing pagination for petitions as it offers range functions that allow you to retrieve items between two indices.
For storing signatures against a petition, I used the Set data structure in Redis where a petition id becomes a key and holds a set of user ids against it i.e. people that have signed that petition. Each signature therefore is an addition operation on that set which is also O(1). If I need to retrieve the signature count for a given petition I can issue a count query to the set which is also an O(1) operation and since sets enforce uniqueness constraints by design the same signer cannot sign a petition twice i.e. fairness.
At the minute, I am using long polling on the TypeScript client in my Angular app to update the signature count for a petition every 10 seconds (only on the petition detail page) but I will be looking for an alternate push based technique using WebSockets or something similar. Long polling is almost never a good idea for a user facing app especially the ones that can be accessed by potentially millions of users for the risk of DDoS-ing your own app at worst and making the network chatty at best. I suppose it depends how long a user keeps a petition page loaded but still. Long polling != a good idea.
Although I am still working on a few things in this application, the current micro-service-ish architecture of this application looks like this:
This application is currently only hosted on my local IIS I still ran some preliminary load tests using Apache Benchmark utility targeting one API end point responsible for loading top 50 currently open petitions. It was able to offer nearly 450 RPS throughput with 350 concurrent requests being issued at any given time. The 99 percentile latency was around 1 second i.e. 99% of all requests were served within that time with a 100% requests being served in 1.4 seconds.

By comparison, the throughput with SQL Server backed API endpoint was around 1/2 that of Redis backed API at best and 1/3 at worst. Although these tests are not indicative of actual performance, its a good way to understand how the application might perform under different circumstances and lets you focus your attentions towards the right efforts.
Of course, all of this is on my local IIS (web gardened for load balancing) with a single node Redis server and the function hosted locally and I haven’t yet profiled the other parts of the system but I think its a fair start. If I deployed it on Azure (assuming the cheapest services that offer limited scalability) and I get the same-ish throughput, I will be fairly happy. Scalability comes at a price that I am personally not willing to pay from my own pocket…yet, unless someone wants to invest in my petition system? 😉 Besides, its very hard to get to the real performance figures for a non production application anyway, it’s all conjecture!
The point of this exercise (besides learning) was to use Azure functions as an implementation mechanism for a micro-service based architecture and start to think in terms of micro-services when starting a project that has or can have independently deployable business components. This kind of thinking can lead to better insights about the domain, help you create simpler architectures and may just help you avoid creating a monolith in the first place.
