
What is an architectural decision?
A decision you and your team make about the “important stuff” or the “architecturally significant” elements of the system you are building. According to Grady Booch, “…significant is determined by the cost of change!” But what is this “cost of change”? I would argue any effort you spend in re-working a solution constitutes “cost of change” for e.g. major refactoring to address technical debt or having to rearchitect the system significantly simply to support new business requirements. Lean manufacturing folks will tell you that rework is waste!
Sometimes it can be financial costs in addition to re-work cost.
Cache In, Cache Out Several years ago, we chose to use a Redis cache cluster on AWS for one of our mission critical services that only runs for a couple of hours a day, and doesn't really have low latency requirements. The reason for that decision are lost to history, but the cost of that decision ended up being monetary because this cache cluster was underutilised and over-paid for. We replaced it with a simple DynamoDB table with on-demand pricing which ended up being a more cost effective alternative with no performance penalty (we're talking a few thousand records, so performance is not even a concern here). Doing so of course also came at a cost of rework because we now had to skip expired records explicitly, something which Redis had been taking care of automatically. This being on the critical path also increased the risk.
Another thing that can make a decision architecturally significant is its potential effect on the desired quality attributes of the system (i.e. the so called -ilities). If I choose synchronous communication over asynchronous then I might be affecting recoverability, availability or performance of the system due to point-in-time coupling with another service.
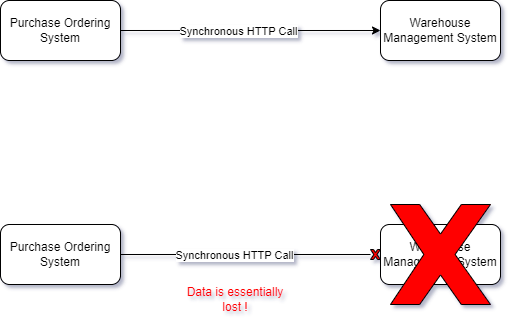

Or if I choose to not make a workflow transactional (i.e. all or nothing), then I could be affecting reliability and recoverability attributes of the system due to the lack of consistency between state changes and side-affects. The independent failure paths there could make it harder to recover from a failure for e.g. what happens when creating purchase order fails but supplier notification succeeds or vice-versa?

Or if I tightly couple the various components/modules of my application architecture or add more unrelated responsibilities to them, I could be affecting long term maintainability (and all its sub-attributes defined in ISO-25010). If I am rolling my own cryptography libraries then I might be compromising the security of the system!
Domain model is another architecturally significant decision, perhaps the most crucial of all because it is the thing that expresses the solution to the business problem and lies at the core of your system that everything else depends on! An unsuitable model will therefore affect everything else! Consider the following generic Hexagonal Architecture diagram:

The domain model is what drives all the subsequent activities in the system so if that’s not fit for purpose, then those design inadequacies will radiate outward to the rest of the system! Its like building on top of a shaky foundation!
All models are wrong, some are useful!
George E.P. Box (Journal of the American Statistical Association, 1976)
Case of the Stuffy Domain Model We once spent 4 weeks to do a domain model rewrite for one of our systems, because we didn't spend enough time modelling the solution domain appropriately and isolating it from the persistence concerns. Our MVP mindset influenced us into making too many assumptions about the data access patterns and they ended up leaking all the way to the frontend application. Our System 1 response to changing requirements had been to just stuff everything into the same monolithic "domain model" we had and "fix it later", than to take a good look at it and ask, "is it still fit for purpose or should we remodel?". Whilst we managed to complete the rewrite without any outages, we gambled with a huge risk due to the large change surface area of the rewrite.
Time spent understanding and modelling the domain well enough is time well spent. We are not chasing 100% perfection and the model is going to have to evolve but we must not be sloppy with the design either. There are lots of great domain driven techniques to do this: Event Storming, Wardley Mapping, DDD Whirlpool, Context Mapping. Its an effort worth spending time on some of these.
Service ownership boundaries, in the same vein, are also a hugely significant element of your architecture and one that is more about people than technology. Creating wrong boundaries or worse, not having any boundaries is a cost you will be paying for years to come as systems and dependencies evolve around shoddy boundaries and harden them.
As a Principal Engineer, I facilitate these practices as much as I can and strive to make boundaries and contexts the first class citizens in any engineering discussions that I engage in with teams. Its a part of our overall engineering strategy, a long term struggle but a worthy one.

Hi Aman! This was an excellent write up that expresses feelings and thoughts that I have been struggling to voice! Do you mind if I shamelessly copy and paste (and possibly condense) some of this content for team reference with source credits pointing here?
hey Cole, I am glad some of my ramblings resonated with you. Do feel free to spread the word! 🙂