
Reader beware: this is a long post, so you might want to get a cup of coffee and settle in if you really want to read it. Also, this is more of a proof of concept code than anything so I am sure I might have missed some key aspects of such a design or glossed over some intricate detail to my own detriment. If so, please feel free to leave a comment. 🙂 With that out of the way, let’s start…
At work, we are planning to break down a single monolithic background running Windows service written in C# (full .NET Framework) into separate components that can be independently – developed, tested and deployed. The motivation to do this has also been that when problems arise, its very difficult to isolate sub-process and just test those, so by breaking it down, we should be able to reduce the time from “idea to production” and also add reliability in testing. The goal is not necessarily to improve performance but introduce loose coupling between discrete components and embrace the idea of eventual consistency and asynchronous messaging.
One of the architectural patterns we are exploring for this problem is Pipes & Filters that has featured in the Enterprise Integration Patterns book. According to this pattern, the whole business process can be divided into smaller asynchronous sub-processes with each one feeding i.e. “piping” its output into the input of the subsequent process(es). At each stage some processing is done for e.g. data enriching, filtering etc and this processing generically is termed as a “filter”.
In this post, I will explore one way to implement this pattern using Azure WebJobs.
The fundamental architecture of P&F looks like this (the message translators are shown for completeness, I haven’t implemented any for this example):

There are 2 key goals with this kind of architecture :
- Sub-steps should be independently testable.
- Sub-steps should be independently executable for e.g. if a step crashes at some point, I should be able to just re-start it from that point and not have to run the whole process.
The inherent asynchrony in this style lends itself perfectly for implementing long running background processes/workflows. Synchronous processes will be too slow and lead to inefficient resource usage.
First off, let’s try and define pipe and filter.
A filter is essentially a facade or an API that encapsulates a business process. For e.g. in this case credit checking process can be encapsulated behind a filter interface. A filter should contain behaviour and data structures specific to its own domain and it shouldn’t really know about any other filters i.e. inter-filter coupling should be really low. It shouldn’t care how its output is consumed and by who, it should have very little infrastructure level concerns mixed in apart from what might be necessary but behind a suitable abstraction. After all business processes shouldn’t have to change if the underlying infrastructure changes.
A pipe just connects two or more filters together to form a workflow. Instead of coupling the filters together tightly, pipes provide a suitable communication abstraction and this decouples the filters. Pipes can provide temporary storage area for the intermediate results of the operations done by a previous filter and for the subsequent filters to read data from. This gives us 2 key benefits:
a) The consuming step doesn’t have to be running at the same time as data is available in the pipes. &
b) If the consuming step crashes while processing data in the pipeline, it doesn’t take the data down with it. This allows for another instance to be started up and pick up the slack.
These pipes could be implemented as asynchronous queues, databases, files etc. but since the EIP book is mostly about queues, I will just use Azure Storage Queues for this implementation.
For the orchestration of pipes and filters, I need a process i.e. executable code. This process can be a normal C# console app or Azure WebJob (in this case) or a Windows service, as long as I can write code to listen on queues. Each such process will take dependencies on at least a filter and additionally an IPipe implementation and anything else that it might need.
In pseudo-code, the orchestration using Azure Web Jobs that I am thinking of, looks like this:
| public class TriggeredOrchestrationProcess | |
| { | |
| public ctor(IDoSomethingFilter doSomethingFilter, | |
| IPipe<DoSomethingMessage> pipe) | |
| { | |
| // take in the dependencies | |
| this.doSomethingFilter = doSomethingFilter | |
| this.pipe = pipe | |
| } | |
| // this will be automatically triggered as soon | |
| // as a message is recieved on the queue that this WebJob | |
| // is listening on. | |
| public void QueueTrigger(string message) | |
| { | |
| // parse the message read from the queue | |
| var inputData = DeserialiseFromJson(message) | |
| // pass the parsed input data to the filter to do some processing | |
| var result = doSomethingFilter.DoSomething(inputData) | |
| // finally, write it out to a pipe (for e.g. queue) for the next | |
| // step in the process. | |
| pipe.Write(result) | |
| } | |
| } |
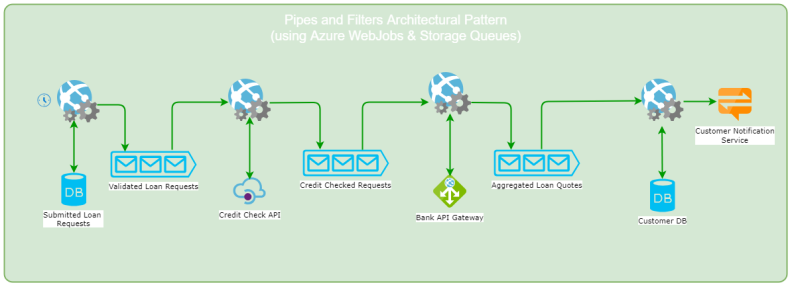
The problem from the EIP book I am using to implement this style on, is building a Loan Quote generation system for a lending brokerage firm. The flow has the following steps:
- Customers submit their loan requests via the brokerage’s web portal all throughout the day.
- Every night these requests get loaded from a database at a pre-set schedule, validated and sent out to external credit agencies for credit checks (actual details of credit checks are irrelevant). For this case, I will just assume that the requests that fail credit checks will be handled manually somehow so I am not going to include it in this piece to keep the scope focussed.
- The successfully credit checked requests are then sent out to various banks that are registered with our brokerage firm, for evaluation and requesting of loan quotes based on their credit history checks. A request from each of the customers is sent to all the registered banks to get a fair spread of quotes.
- Each of the banks then responds back with a quote for each of the customer requests which are then aggregated by user and forwarded to a customer notifier which will send out e-mails with loan quotes to the registered customers.
NB: It should be abundantly clear from the above flow, that the final results delivered to the customers won’t be delivered soon after submitting the loan requests but some time later(a few hours, may be even a day or so). This is called Eventual Consistency and it is a cornerstone of long running workflow processes like these. If your application needs to respond to user requests soon after they are issued, then eventual consistency may not be a desirable thing. It really depends on the type of the system and its key objectives.
Represented visually, the above flow will look like this:
Let’s start with the below interface for a pipe:
| public interface IPipe<T> | |
| { | |
| Task Write(T payload); | |
| } |
To me, a filter has too wide a variance to have a generic top level interface so I can create this per use case for e.g. ICreditCheckFilter whose responsibility it is to perform credit checks on loan requests submitted by customers of a loan brokerage firm. For e.g. here is what my ICreditCheckFilter interface looks like:
| public interface ICreditCheckFilter | |
| { | |
| Task<EnrichedLoanRequest> PerformCreditCheck( | |
| LoanRequest loanRequest); | |
| } |
An example of the Azure WebJob process code that orchestrates the ICreditCheckFilter and the corresponding pipe, might look like this (logging and instrumentation code removed for brevity):
| public class Functions | |
| { | |
| private readonly ICreditCheckFilter creditCheckFilter; | |
| private readonly IPipe<EnrichedLoanRequest> pipe; | |
| public Functions( | |
| ICreditCheckFilter creditCheckFilter, | |
| IPipe<EnrichedLoanRequest> pipe) | |
| { | |
| this.creditCheckFilter = creditCheckFilter; | |
| this.pipe = pipe; | |
| } | |
| public async Task ProcessQueueMessage( | |
| [QueueTrigger("submitted-loan-requests")] string loanRequestPayload, | |
| TextWriter log) | |
| { | |
| var submittedLoanRequest = JsonConvert | |
| .DeserializeObject<LoanRequest>( | |
| loanRequestPayload); | |
| var enrichedLoanRequest = await creditCheckFilter | |
| .PerformCreditCheck(submittedLoanRequest); | |
| await pipe.Write(enrichedLoanRequest); | |
| } | |
| } |
The process reads the input data from a queue named “submitted-loan-requests”, deserialises it into the LoanRequest structure and passes it to the credit check filter to perform credit check and then takes the result of that operation and writes it to a queue named “credit-checked-loan-requests” via the IPipe implementation. An IPipe implementation that I wrote for this process looked like this (don’t worry about the SimpleQueueHelper class, it is just a wrapper library that I wrote to abstract Azure Storage Queue connection set-up, to send a message to the queue):
| public class QueueBackedLoanQuoteSubmissionPipe | |
| : IPipe<EnrichedLoanRequest> | |
| { | |
| // this is just a simple helper library I wrote | |
| private readonly SimpleQueueHelper queueHelper; | |
| public QueueBackedLoanQuoteSubmissionPipe( | |
| SimpleQueueHelper queueHelper) | |
| { | |
| this.queueHelper = queueHelper; | |
| } | |
| public async Task Write(EnrichedLoanRequest payload) | |
| { | |
| await queueHelper.SendMessage(payload); | |
| } | |
| } |
The next stage that sends these credit checked loan requests to banks to get loan quotes, will pick up the messages from the queue:
| public class Functions | |
| { | |
| private readonly ILoanRequestSenderFilter loanRequestSenderFilter; | |
| public Functions( | |
| ILoanRequestSenderFilter loanRequestSenderFilter) | |
| { | |
| this.loanRequestSenderFilter = loanRequestSenderFilter; | |
| } | |
| public async Task ProcessQueueMessage( | |
| [QueueTrigger("credit-checked-loan-requests")] string message, | |
| TextWriter log) | |
| { | |
| dynamic creditCheckedLoanRequest = JsonConvert.DeserializeObject(message); | |
| var loanQuoteRequest = new LoanQuoteRequest | |
| { | |
| BSN = creditCheckedLoanRequest | |
| .OriginalLoanRequest | |
| .CitizenServiceNumber, | |
| CreditRating = $"{creditCheckedLoanRequest.CreditCheckReport.CreditScore} " + | |
| $"({creditCheckedLoanRequest.CreditCheckReport.CreditRating})", | |
| LoanAmount = creditCheckedLoanRequest | |
| .OriginalLoanRequest | |
| .RequestedLoanAmount | |
| }; | |
| await loanRequestSenderFilter | |
| .SendLoanRequestToRegisteredBanks(loanQuoteRequest); | |
| } | |
| } |
And will submit the requests to each of the registered banks via a REST API call inside the filter implementation:
| public class LoanRequestSenderFilter : | |
| ILoanRequestSenderFilter | |
| { | |
| public async Task SendLoanRequestToRegisteredBanks( | |
| LoanQuoteRequest loanQuoteRequest) | |
| { | |
| var allRegisteredBanks = RegisteredBanks.All(); | |
| foreach (var bank in allRegisteredBanks) | |
| { | |
| // perform the bank API call | |
| } | |
| } | |
| } |
And on it goes, I can add more steps in a similar way if the business process changes in the future…the goal, however, is not how you would implement a loan quote generation system but to show a way to break apart a monolithic workflow into independently executable and testable asynchronous sub-steps.
The next thing that I want to explore is setting-up Dependency Injection with Azure WebJobs and get all the goodness of SOLID principles and loose coupling between processes. Apparently, with the latest version of WebJobs SDK, Microsoft have made it fairly easy to set up DI with WebJobs. There are 2 things I need to do to inject dependencies from outside in:
- Use a DI container to wire-up all the dependencies. for e.g. Ninject, Autofac, SimpleInjector, Microsoft’s DI extension etc.
- Tell WebJobs to use this DI container to resolve all dependencies.
The bootstrapping code for CreditCheck WebJob looks like this:
| internal class Program | |
| { | |
| private static void Main() | |
| { | |
| var dashboardConnectionString = ConfigurationManager | |
| .AppSettings["AzureWebJobsDashboard"]; | |
| var storageConnectionString = ConfigurationManager | |
| .AppSettings["AzureWebJobsStorage"]; | |
| // initialise the DI container | |
| var svcCollection = new ServiceCollection(); | |
| // add all dependencies | |
| svcCollection.AddScoped<IHttpMessageHandlerFactory, | |
| MockHttpMessageHandlerFactory>(); | |
| svcCollection.AddScoped<ICreditCheckFilter, | |
| CreditCheckFilter>(); | |
| svcCollection.AddScoped<IPipe<EnrichedLoanRequest>, | |
| QueueBackedLoanQuoteSubmissionPipe>(); | |
| svcCollection.AddSingleton(_ => | |
| SimpleQueueHelperFactory.Create( | |
| "credit-checked-loan-requests", | |
| storageConnectionString)); | |
| // this line is crucial for all the dependencies | |
| // to be resolved correctly. | |
| svcCollection.AddTransient<Functions>(); | |
| var config = new JobHostConfiguration(); | |
| config.DashboardConnectionString = dashboardConnectionString; | |
| config.StorageConnectionString = storageConnectionString; | |
| // tell the config to use the custom IJobActivator | |
| // implementation with the IServiceProvider DI container | |
| config.JobActivator = new MyActivator( | |
| svcCollection.BuildServiceProvider()); | |
| var host = new JobHost(config); | |
| // The following code ensures that the WebJob will be running continuously | |
| host.RunAndBlock(); | |
| } | |
| } |
In this case I am using Microsoft’s inbuilt DI extensions package to do 1. By default the scaffolded web jobs class creates a static method to process queue messages which the JobHost invokes when a message appears in the queue. I can easily make the method an instance method and as long as I have a parameter less constructor in the class, the job host will be able to invoke that method too. However, having a parameter-less constructor is not very useful when you want to do constructor injection of dependencies. So to address this, I can add a constructor with dependency parameters and then I will add a transient instance of my web jobs class to my DI container (as shown in the code above). The effect this will have is that a new instance of the handler class will be created to deal with each incoming message which is fine so long as I don’t have any shared mutable state which I really shouldn’t if I want horizontal scalability and want to process messages in parallel on separate threads.
Sidebar: Interestingly enough, the JobHostConfiguration class exposes a Queues property where I can set the various thresholds like what should be the polling interval, how many messages should I dequeue in one go, at what message count should I dequeue the next batch of messages etc. A web job by default will dequeue 16 messages in one go and process them in parallel regardless of a single or transient handler instance because the assumption is that there is no mutable state in the class that might be shared between threads leading to hard to diagnose issues like race conditions, deadlocks, starvation etc. Besides, web job instances are built to be expendable state created in one web job process instance wouldn’t be available in another process level instance. So let’s just not to do that! Push comes to shove, out of process distributed caches like Redis, Memcached should be used but they come with their own set of problems. Do your homework!

Next, in order to set my DI container as the default for this WebJob, I create an implementation of IJobActivator and override the default one in the JobHostConfiguration::JobActivator property:
| internal class MyActivator : IJobActivator | |
| { | |
| private readonly IServiceProvider serviceProvider; | |
| public MyActivator(IServiceProvider serviceProvider) | |
| { | |
| this.serviceProvider = serviceProvider; | |
| } | |
| public T CreateInstance<T>() | |
| { | |
| return this.serviceProvider.GetService<T>(); | |
| } | |
| } |
Once this is done, I can inject my dependencies as usual using constructor injection and resolve services using interfaces which will allow me to change implementations without changing the WebJob code itself.
Now, onto one of the most crucial thing in this exercise: testing. While writing code, testing actually comes first but for writing blog posts, I suppose it doesn’t matter if I mention it towards the end, does it? 🙂
Building distributed asynchronous systems means testing becomes that much more important to ensure system works as a whole but also the sub-systems work as a unit too. The first step is therefore to add unit tests at a sub-system or step level to ensure each step can read its input, process it and produce an output. As an example, I can write unit tests for CreditChecker system like so:
| [Fact] | |
| public async void Given_One_or_More_Loan_Requests_Each_Is_Enriched_With_Credit_Score_Info() | |
| { | |
| IReadOnlyCollection<LoanRequest> mockLoanRequests = MockData(); | |
| ICreditCheckFilter creditCheckFilter = new CreditCheckFilter( | |
| new MockHttpMessageHandlerFactory()); | |
| List<EnrichedLoanRequest> loanRequestsWithCreditReport = | |
| new List<EnrichedLoanRequest>(); | |
| foreach (var mockLoanRequest in mockLoanRequests) | |
| { | |
| loanRequestsWithCreditReport.Add(await creditCheckFilter | |
| .PerformCreditCheck(mockLoanRequest)); | |
| } | |
| Assert.True(loanRequestsWithCreditReport.Any()); | |
| Assert.True( | |
| loanRequestsWithCreditReport.Count(x => x.CreditCheckReport != null) == | |
| loanRequestsWithCreditReport.Count); | |
| } | |
| private IReadOnlyCollection<LoanRequest> MockData() | |
| { | |
| return new[] | |
| { | |
| new LoanRequest | |
| { | |
| CitizenServiceNumber = "12345", | |
| RequestedLoanAmount = 1000.0m | |
| }, | |
| new LoanRequest | |
| { | |
| CitizenServiceNumber = "12346", | |
| RequestedLoanAmount = 2000.0m | |
| } | |
| }; | |
| } | |
| public class MockHttpMessageHandler | |
| : HttpMessageHandler | |
| { | |
| protected override async Task<HttpResponseMessage> SendAsync( | |
| HttpRequestMessage request, | |
| CancellationToken cancellationToken) | |
| { | |
| HttpResponseMessage httpResponseMessage = | |
| new HttpResponseMessage(); | |
| httpResponseMessage.Content = | |
| MockContent(request.Content); | |
| httpResponseMessage.StatusCode = HttpStatusCode.OK; | |
| return await Task.FromResult(httpResponseMessage); | |
| } | |
| private HttpContent MockContent(HttpContent content) | |
| { | |
| string mockJsonContent = "{\"BSN\":\"12345\", \"CreditRating\":\"A\", " + | |
| "\"Score\":\"9\", \"Status\":\"Good credit\"}"; | |
| return new StringContent( | |
| mockJsonContent, | |
| Encoding.UTF8, | |
| "application/json"); | |
| } | |
| } | |
| public class MockHttpMessageHandlerFactory | |
| : IHttpMessageHandlerFactory | |
| { | |
| public Uri BaseUri => | |
| new Uri("http://localhost:1111"); | |
| public HttpMessageHandler Create() => | |
| new MockHttpMessageHandler(); | |
| } |
Basically, I want to assert that the results of the credit check process are as expected but since this is a unit test and I may not have access to the external credit check API yet, I can mock the HttpMessageHandler that will help my ICreditCheckFilter just return a dummy response for each credit check request made (this is common pattern used with HttpClient called delegating handler). I can then assert on it and see if my test passes or fails. The goal with this test is not to test the external services but my own components and make sure their innards work properly. It just so happens in this case that there is not a whole lot of business logic and most interactions are with external parties so the tests might seem a little anemic but enough to give you an idea about one possible approach to testing such a system! Also, I haven’t been too pedantic about null checks in this (non-production) example.
I can similarly write other test cases (and for other components) that will simulate different response codes from the external services so I can make sure that my components handle these response codes appropriately. I don’t have to have queues hooked up to my tests either, I can just serialise/deserialise JSON strings in memory to simulate reading from/writing to queues. Again, the goal is not to test whether the queues work, Microsoft have already done that for me, thankfully!
Some of the key points in this kind of decoupled architecture to keep in mind are:
- Data from each step has to be parseable by the subsequent step. Even though we are building steps for independent execution, they are implicitly coupled by the data structure schema. A simple way to avoid class/DTO level coupling is to duplicate DTOs per process, for e.g. the LoanRequest DTO in this example is duplicated in LoanRequestRetriever and also in CreditCheck process. Excessive DRYness in the system would inevitably lead to coupling and headaches, try not to cling on too hard to principles such as DRY.
- The processing is “pipelined” i.e. the next step in a process is processing messages while the previous step is queuing in the messages. No step has to wait or block for the queuing to finish to start its own processing. Its better to create one message per item instead of one big message that contains all the items because its more space efficient to store one item in queue rather than thousands in one single message (Azure Storage Queues restrict messages at 64KB natively and larger messages are stored using Blob Storage which is adding complexity). It also takes the load off the subsequent steps because they only have to process one message per run rather than trying to dequeue a massive message and then spend time processing it, potentially becoming a weak link in the chain. I can also leverage WebJobs’ parallelisability by processing one message per thread and improve throughput.
- The whole process can be kicked off either manually or automatically in response to an event for e.g. timer firing, database record being inserted, message appearing in the queue etc.
- Stuff like queue names etc should be configurable and shouldn’t be hard coded. With Azure WebJobs, its very simple to do i.e by providing an implementation of INameResolver to the JobHostConfiguration and reading the queue name from a config file. In this example, I have also made sure that queues are ready beforehand they can either be created directly in Azure portal or by running ARM templates using Powershell.
- Good logging and instrumentation strategy should be in place to diagnose problems in such a distributed system. Correlation Ids will help in tying up a request through all the steps of the process during a debugging session. In this example, loan request id could be a good candidate for a correlation id or really anything that is not sensitive yet gives enough context. In this example I have used Serilog for some basic logging with a Console sink but can switch to a Splunk sink or Azure App Insights sink.
- Appropriate resilience policies should also be put in place so operations can be retried safely without taking the whole process down. With Azure WebJobs, you get resilience out of the box, if an exception happens in the called code it will simply retry dequeuing messages 5 times before giving up & moving them to a poison queue. You can also implement your own resilience policies for e.g. retries and circuit breakers using Polly for the code that is not covered by resilience out of the box, keep in mind though, for retries the operation being retried must be idempotent i.e. the result of doing that operation more than once should be the same as that of doing it once. One way of self-implementing resilience policies has been shown in the code for this example.
- For easy debuggability, the process should be easily executable end to end or from any of the intermediate steps. For e.g. in this case, you can dump some test messages into the “submitted-loan-requests” queue and kick off the credit check process without invoking the whole process end to end. This is one of the pain points we have with the application at work, the whole thing needs to be run everytime, we can’t just run from point “x” in the process.
- CI/CD pipeline needs to be appropriately set up to automatically deploy all the processes properly to correct VM instances or app services if using Azure PaaS. One cloud provider agnostic way to do this is using Cake scripts that are part of the source code and live in source control repository. For VSTS there is even a plugin on the marketplace that can be enabled to allow you to add Cake script execution as one of the build steps (perhaps even the only one you’d need!) and deploy to Azure. Shared infrastructure code could be deployed as nuget packages, although in this example I have just let it be a project level reference and haven’t yet put in a good deployment strategy in place. That shall be the next post!
- Finally, for improved throughput and better resource utilisation, these individual web jobs i.e. sub-steps could even be run in multi-instance mode but this would depend on how many messages you need to process in your long running workflow to ensure optimal resource utilisation.
Hope this has been useful. The current code is on my GitHub , if you want to run it you will need to install Azure WebJobs SDK on your machine. Also, please note as of this writing, you can’t run WebJobs locally if you are using Local Storage Emulator so for this code to work, you would need at least a free Azure subscription and actual queues set up in Azure or you could write your own queue listeners with plain old console apps and simple polling with event handlers.

kudos to your effort , for a moment i thought that i am in room and doing whiteboarding and technical discussion with you … really appreciate your efforts and design thinking from moving to monolithic to microservice … one question though , why you have choosen azure web job instead of azure function
Hey Phani, I am glad you found this interesting and useful! When I wrote the post, Azure functions had a more strict execution time limit (don’t remember now what it was) so I opted for web jobs that can be long running. Also the service we refactored at work was a Windows Service and Web Jobs were the closest analog for that. Please also bear in the mind that at work we use AWS not Azure, but because at the time I was more well versed with Azure than AWS I chose to implement this style on Azure to see how would the mechanics of the pattern pan out.