In part 3, I looked at creating a repository for the domain model to persist and retrieve the objects. In this post, I look at building Application Services for this domain model which is the next layer of abstraction higher up from low level detail.
Application services can be loosely compared with the business logic layer of the yesteryear with one key difference, application services don’t actually contain any business logic neither they enforce any business logic. All the business logic is encapsulated in the domain model objects and domain services. Application services provide a facade to the domain model and also provide transaction control, security enforcement (for e.g. authorisation to do something) and any other cross cutting concerns that can’t be neatly tucked away anywhere else.
They sit between consuming client i.e. web app, desktop app etc and the domain model+repository:
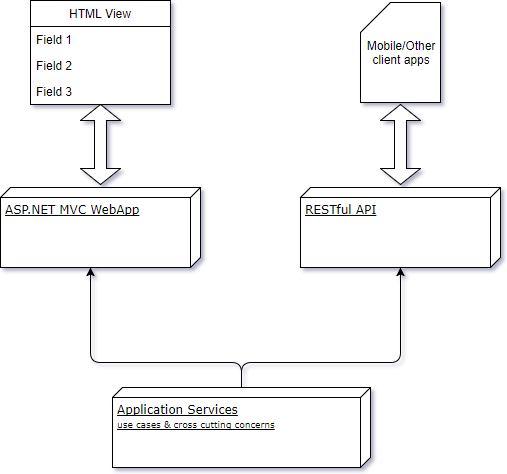
Its useful to think of application services as a course grained API for the use cases that the application is supposed to deliver to the users. These use case methods are classed in the following 2 ways:
- Read-only: in these use cases the data is retrieved from the repositories for read-only purposes for e.g. reporting methods.
- Read+Write: these use case methods retrieve data in order to alter it and then save it back following the get -> mutate -> update pattern.
The direct consuming client of the application services can be (as shown in the sketch above): an MVC web application with an HTML front end, a REST API, a WinForms app and any other application type (remember the architecture block diagram from part 1?). Using application services decouples the application core i.e. domain model from the presentation/delivery mechanism of the day. I might want to offer the application functionality not only as a web application but also as RESTful API that can be consumed in variety of ways. I might also have an internal WinForms tool for back-office purposes but I shouldn’t have to put significant efforts to make the application compatible with WinForms app. Application services provide that flexible integration and extension.
For my expense tracking application, I went with the following simple interface:
public interface IPeriodService
{
Task AddNewExpenseAsync(DateTime expenseDate,
decimal amount,
string description,
Guid potId,
Guid periodId);
Task CreateNewPeriodAsync(DateTime start, DateTime end);
Task<IEnumerable> GetAllPotsInCurrentPeriodAsync(Guid periodId);
// .. more use case methods
}
As you can see, these methods accept only primitive types as parameters and either are void types i.e. no return values as would be the case with many write type operations or they return the domain object(s) as would be the case with almost all read type operations.
I prefer to return domain objects from the application services out to the consuming client that can then transform it into a structure most appropriate for its use. It decouples the application services from the presentation concerns and this is what makes it truly re-usable across all application types. If I am using ASP.NET MVC, I will convert the domain object result into a ViewModel most appropriate for my views. This ViewModel could combine results from multiple aggregates and show them as one view (I will describe this in more detail in the final post of this series). If I am using a RESTful API, I will convert the domain object(s) into a DTO (Data Transfer Object) that’s optimised to include just the data that’s required by the use case. The DTO approach (which is a polarising topic in the software architecture community) reduces the amount of data that needs to be serialised across the wire for a remote client (either as JSON, XML or binary) and thus is more beneficial for the API type scenarios where use cases are neatly defined.
The other reason why in general the domain objects should be converted into one form or the other is that the domain objects are not supposed to have a public parameterless constructor in them which makes them unserialisable – a crucial requirement for remote calls. The DTOs/ViewModels however are just dumb data structures so they can be serialisable i.e. they can have a parameterless constructor (which is the default in C# anyway if you don’t define any constructors).
The implementation of the above application service interface looks like this:
public class PeriodService : IPeriodService
{
private IPeriodRepository periodRepository;
private IReportingRepository reportRepository;
private IInstrumentationHelper instrumentationHelper;
public PeriodService(IPeriodRepository periodRepository,
IReportingRepository reportRepository,
IInstrumentationHelper instrumentationHelper)
{
this.periodRepository = periodRepository;
this.reportRepository = reportRepository;
this.instrumentationHelper = instrumentationHelper;
}
public async Task AddNewExpenseAsync(DateTime expenseDate, decimal amount,
string description, Guid potId, Guid periodId)
{
Stopwatch timer = Stopwatch.StartNew();
Period period = await this.periodRepository.GetOneAsync(periodId);
period.MakeExpenseAgainstPot(amount, description, expenseDate, potId);
await this.periodRepository.UpdateAsync(period.Id, period);
timer.Stop();
this.instrumentationHelper.TrackTrace($"
{nameof(IPeriodService.AddNewExpenseAsync)} took
{timer.Elapsed.ToString()} to finish!");
}
public async Task CreateNewPeriodAsync(DateTime start, DateTime end)
{
Period newPeriod = new Period(start, end);
await this.periodRepository.AddAsync(newPeriod);
}
public async Task<IEnumerable> GetAllPotsInCurrentPeriodAsync(Guid
periodId)
{
Period period = await this.periodRepository.GetOneAsync(periodId);
return period.Pots.AsEnumerable();
}
//.. more method implementations
}
As you can see, this service takes dependencies on all the repositories it needs and any infrastructural concerns that it needs for e.g. instrumentation logging in this case.
All the method implementations are one of the 2 types I described earlier. Its important to understand that the application service methods do not correspond to CRUD operations one-to-one but internally translate the use case into one or more of CRUD operations. For e.g. the AddNewExpenseAsync(…) method, uses the PeriodRepository to first load the period aggregate, then it invokes the MakeExpenseAgainstPot() method against the aggregate that mutates its state i.e. adds a new expense against the pot and then finally, calls the UpdateAsync() method of the repository to persist the changes back to the database. This is the fundamental of all write methods in application services in general.
The GetAllPotsInCurrentPeriodAsync() call however, is a read-only call so it uses the repository to load the period and returns the collection of Pots. Notice all the collections being returned are IEnumerable(this could also be IReadOnlyCollection) and not List or any other modifiable collection type. I don’t want the consuming client to inadvertently or maliciously make any changes to the collections returned by the application services as it may compromise the consistency of the aggregate. For e.g. you wouldn’t want to do “pots[0].Allocation = -100” or even worse “period.Saving = 2000000”! These values are updated internally as a result of adding/reversing expenses and NEVER directly. Although, the application is disconnected in nature so very likely won’t commit those changes to the database but changing the return value manually will still garble user’s view of the application which is still bad!
What if an application service method needs to perform a complex operation that needs more than an acceptable number of individual parameters?
public class PeriodService : IPeriodService
{
public void ComplexOperation(string param1,
int param2,
int param3,
decimal param4,
string param5)
{
//..some complex operation using these passed in params
}
}
For these kinds of cases, I might use a Command object defined in a shared assembly referenced by both application services assembly and the consuming application. The command object is basically a POCO object that encapsulates all the parameters I need for the operation:
// defined in a shared assembly that can be used by the application services
// as well as the ASP.NET MVC controllers (or any other application type).
// For ASP.NET MVC this could be bound using MVC model binding to auto-populate
// it otherwise, it could also be manually created in the controller and passed // onto the application services.
public class ComplexOperationCommand
{
public string Param1 {get;set;}
public int Param2 {get;set;}
public int Param3 {get;set;}
public decimal Param4 {get;set;}
public string Param5 {get;set;}
}
The application service method signature then becomes:
public class PeriodService : IPeriodService
{
public void ComplexOperation(ComplexOperationCommand
complexOperationCommmand)
{
//.. use the param values from the command to perform the complex
// operation
}
}
This approach loosely follows the CQRS pattern where commands (or write operations) are separated from the queries (or read operations). This makes the intentions and use cases clear as to what the parameters of a use case method relate to. I would highly recommend reading on CQRS and Command patterns because I haven’t directly used these patterns in my expense tracking application so far so I only have an approximate idea on their correct usage. I have only described the Command pattern very loosely, its a little bit more work implementing it properly because you need to create command handlers which could range from in-app methods that handle a command to temporally decoupled command handlers for e.g. Azure Web Jobs that process the commands received via Azure Message Queues.
A word of warning though, DTOs/Commands should only be used when they are structurally and semantically very different from the actual domain objects. If they are very similar meaning the domain model is very simple CRUD style model, adding these multiple layers of object representations will add code duplication, complexity and maintenance overhead to the application and not much benefit. Best avoided in that case! Although, my best guess is that in any non-trivial enterprise application, there are definite advantages to be had using DTOs/Commands and Domain Driven Design in general even though it may not appear so at the start.
A big part of designing architecture for any enterprise application is asking the kinds of questions that: help clarify the overall business objective, identify the scale and complexity of the application and the kinds of use cases that the application will need to cater for. Things like use cases can tell you a lot about the style of the application i.e. whether its CRUD or more like DDD or any other style. Many applications will have some degree of CRUD-ness in them for e.g. administration component of any application where you want to bulk import data without any special business rules (product inventory, customer details etc) but its about finding those cases and handling them appropriately rather than going for the “one size fits all” approach that makes the difference. I recently came across Jimmy Bogard’s “vertical slice” architectural style which I think is quite cool as it seems to allow choosing architectural style by use cases.
In the final post, I will walk through the consuming application built using ASP.NET Core MVC and how it interacts with the application core to round this 5 part series off.

2 Replies to “Building Domain Driven Architecture in .NET – Part 4 (Application Services)”