
As software engineers/architects, we all understand that technical debt must not be allowed to build up overtime otherwise, it can grind your team velocity to a halt and hurt the evolvability of your systems.
There are many posts and articles that expound the virtues of paying back the tech debt and philosophise at great lengths about the various design patterns that can improve the design of the code. In this post I’d like to tackle the more pragmatic and real life aspects around tech debt from my perspective:
- Communication of tech debt to the team (including Product Owners)
- Managing and paying this debt in a visible, incremental and safe manner and
- Value proposition of addressing technical debt
Product owner’s dilemma
Product Owners will often have questions and concerns when you bring up the matter of technical debt with them.
Why should we focus on something that no user will ever really see or benefit from, as opposed to building these highly valuable features that the users do want?
Its a very valid question…to an extent…because POs inherently might not understand why some out of band technical work is being done that wasn’t requested by a user or wasn’t on the roadmap. But as engineers/architects, we know the real cost of technical debt and its as much our responsibility to communicate it in a way that makes sense for stakeholders, as it is to actually pay it off and keep our systems delivering value today and tomorrow.
An Anti-Pattern (or a Myth)
All too often I hear from engineering teams that they need to “convince” their POs/managers to let them address technical debt or…worse…get “permissions” from them to do so.
This is wrong! We do not! Let me say that again, we do not need permission to address problems in the systems we build to support the business! The word “alignment” also has become a proxy for permission in this regard and its just daft!
Product Owners care about risk to value delivery (delays, cost-overruns, persistent failures/outages, lack of product reliability) and so should we. If we can plan the technical debt work such that it de-risks delivery and still delivers value continuously, no PO says “No” to that (exceptions abound).
What I have seen POs (and even teams) have difficulties with is when the work is not well planned or de-risked and looks to be becoming a multi-sprint, multi-quarter project that risks halting business value delivery entirely. This is a pickle I wouldn’t wish on any team or PO because its very hard to defend in front of the C-suite, especially, when we know that we could have prevented getting into it from the beginning.
Who are the stakeholders…really?
Its critical to understand that software (architecture) has two main stakeholders:
- Business users, and
- Developers
This might come as a bit of shock to the uninitiated but its true! Whilst its the business users that are deriving the business value out of the software we the developers, have built for them. Its us the developers, who are responsible for maintaining and evolving it.
We live in it all day every day! How can we possibly only ever meet the needs of the users without sparing a thought for the developers who have to maintain that codebase? And if that codebase is a pile of mess, even though the users might not see it, it will make it incredibly frustrating for developers to work on it and keep evolving it. Eventually, this will wear their motivation down and make for an unhappy team! No PO (should) want that!
This Dilbert strip, for me, covers this succinctly 😀

The good, the bad and the ugly
Its important to understand that not all tech debt is equal or bad, the following factors play a huge role in determining the value and severity of the debt:
- Frequency of change
- Path criticality
- Impact on and relevance to, the business roadmap
The SEI book Managing Technical Debt (the inspiration for this post’s title) introduces this pseudo-scientific graph called the Tech Debt Timeline:

The idea being that up until a certain point, tech debt could be an asset because it can make you go faster (because you are not engineering for perfection or stability but just to get the product out the door and get user feedback).
But beyond that point (Tipping Point in the graph above), the team will start feeling the pain of that initial debt in their every day work to the point that it will make it harder and harder for them to keep evolving the system to meet the future business needs. Then you reach a point where you MUST remediate the debt before you do anything either by undoing the past sins or just re-writing from scratch (depending on how far gone you were). This is certainly not the place you want to be in for too long, because it takes time away from the business critical work and could jeopardise the roadmap.
Making tech debt visible and accessible
For the last few months, in our team we’ve been experimenting with a tech debt management process of our own devise to see if we can make this techno-mumbo-jumbo-debteroo more visible for all team members and more accessible for our Product Owner.
First off, we never dedicate x% of our sprint to tech debt, we believe in continuously improving our systems incrementally. Dedicated tech debt sprints, for me, is an anti-pattern because during that time you are not delivering business critical updates but also, it seems like an excuse to let the debt build up and pin your hopes on that x% of the sprint to pay it all off. May be there is a way that can work, I’ll be keen to know!
For planning and tracking purposes, we divided a somewhat umbrella term technical debt into 2 distinct groups:
- Organisational Tech Debt: this is debt that is “enforced” upon teams by organisational constraints for e.g. we want to run on Linux servers so all .NET Framework apps need to be migrated to .NET Core! Or we are being asked to upgrade our Redis cache cluster version for better balance between performance and cost etc.
This debt is not due to team’s decisions but team’s decisions could make it easier or harder to make these kinds of changes to their architectures. Usually, org tech debt will have a fairly clear timeline and cost incentives which can make it really clear for the stakeholders like POs to understand it from a time and cost perspective and prioritise it on the product backlog. - Team Tech Debt: this very obviously belongs firmly in the development team’s camp. Decisions made earlier on in the project lifecycle to expedite a working version, that don’t get addressed even after MVP version is done, can lead to much of this tech debt. Other times, it could just be that the team simply didn’t have enough information at the time to make the most robust decision so they took a pragmatic albeit less than optimal approach to solve a problem.
Debt is not always in code either, sometimes its in outdated documentation or architectural diagrams or even in the development process itself!
The problem is that this kind of debt isn’t exactly quantifiable in monetary, time or user value terms, and that’s what makes it really hard for POs to understand and help prioritise it. If they cannot understand it then chances are that this “technical noise” might just end up getting squeezed out of the backlog eventually (true story).
We actively try and educate non-tech stakeholders to steer clear of artificial metrics like, “no of errors/bugs saved per month” or “money saved by refactoring some code” etc. because these “metrics” imply a false correlation with debt which makes them fairly meaningless.
So then how do we communicate this well enough to justify putting it on the backlog and pursue it with a bit more buy-in?
First, when refining the business epics/stories on our backlog, we always look at the code that could be affected by this story. We try to identify any potential technical debt that could impede the business relevant changes either directly or indirectly, now or in the near future.
Once we have identified the problem child, we might do one of 2 things:
- If the technical debt is sufficiently small scoped for e.g. refactoring code/tests for readability, maintainability or testability, we add it to the business story itself with the intention of addressing the tech debt as a part of making business related changes. The story template that we use for this looks something like this:
CONTEXT Domain problem description
ASSOCIATED TECH DEBT
- Problem: description of the technical debt and whether its in tests, code, UI or build scripts.
- Impact: if applicable and known, should briefly explain what is the impact of this debt on our ability to make business changes
- Proposed Resolution: at a high level how this item can be addressed for e.g. refactoring approaches, application of appropriate design pattern etc.
- Value: benefits of resolving this debt as a part of this story
ACCEPTANCE CRITERIA
List of criteria that the technical solution needs to satisfy
...
- If the scope of the problem is wider than the immediate system under consideration then we will first create a technical debt story that’s designed to address this problem and block the business story behind it For e.g. if we need to change how certain calculations work but we realise that these calculations are duplicated in multiple modules/systems, then this debt deserves its own story. The PO is always in the loop about these decisions.
Additionally, to track any ad-hoc tech debt items we have what we call a Wall of Tech Debt which is essentially a digital canvas with e-sticky notes stuck along value – effort axes. Value on x-axis and effort on y-axis.

The team adds whatever adhoc tech debt items we think might be worth discussing and creating an addressal plan for. Then every once every week, we review these items and put them a bit more “accurately” along the effort-value axes.
We determine value roughly by looking at what exactly is the item aimed at resolving and just how much of a pain it is currently. For e.g. simplifying the test suite in which we work a lot everyday, could yield a lot of readability, maintainability and quality benefits so we would class that as high value. Whereas something like moving a hard coded list of e-mail addresses from code into a database, could be classed as low value if the list doesn’t change very frequently and working with the hard coded list is easy enough if not perfect.
It doesn’t stop there though, value can also be determined in terms of the following architectural quality attributes:
- Performance (does the proposed change measurably address a known performance issue in our critical path? We might do a safe experiment in a non-prod environment to measure this.)
- Evolvability (does the proposed change make the design extensible to meet the future challenges with relative ease? Often looking at the roadmap and asking PO direct questions about future needs can help ascertain this to some degree)
- Observability (does the proposed change allow us to monitor the system in production better or ask questions of it to understand its run time behaviour and diagnose issues better or quicker?)
- Security (does the proposed change improve the security of the our system?)
- Maintainability (does the proposed change reduce coupling or break up a large component into smaller ones for improved maintainability and testability? or does the change add/improve documentation for the same effect?)
- Cost (does the proposed change save a significant amount of money per month/quarter/year? For Org Tech Debt this is usually quantifiable, not so much for Team Tech Debt level, unless, we choose to downscale our infrastructure to save costs).
Because its difficult to associate tech debt with quantifiable benefits/metrics, we make sure to mention these value benefits as clearly as possible in the story on our backlog.
Effort is usually determined by essentially timeboxing the work, if we cannot reasonably address the item in a couple of hours, it gets marked as high effort and a story on the backlog is created for it where it will be prioritised based on the value of the item and relevance to any roadmap item.
If there is a strict deadline on a piece of tech debt (usually this happens with org level tech debt items) then we tend to prioritise it accordingly. If the effort is low and deadline is distant, we might schedule it for later. If the effort is high and deadline is proximal, then we tend it prioritise it sooner.
The process in its entirety looks like this. The red, green and blue post-its describe the kind of changes that go in that lane. Green ones are quick fixes and red ones are longer terms changes that we will do over several sprints.
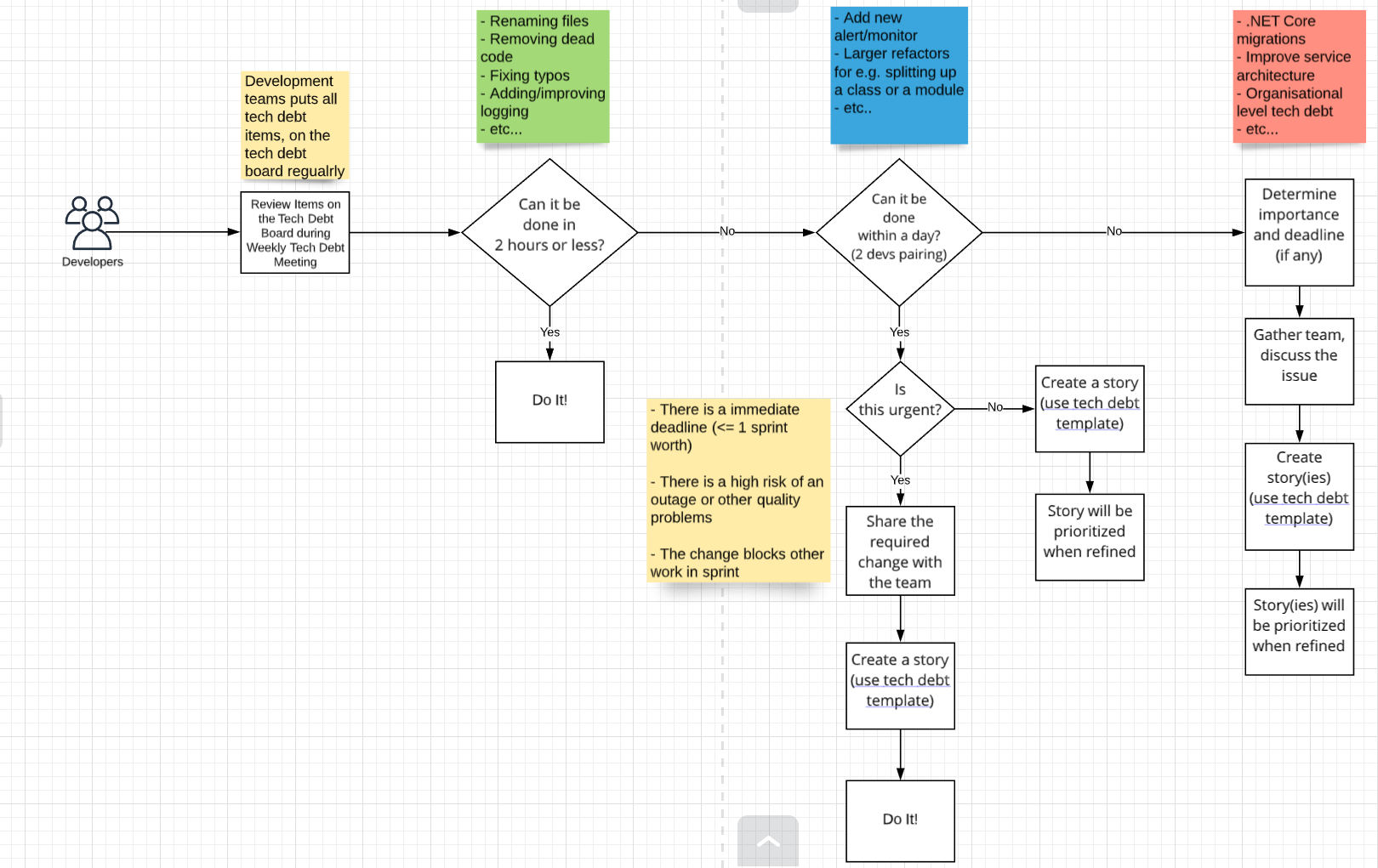
A majority of the tech debt items fall in either the blue or green lane, only large and cross-service tech debt items tend to get addressed in the red lane and span across multiple sprints.
In Sum…
We’ve observed since having employed this process that we’ve become a lot more diligent with our technical debt identification, more articulate with its value assessment and clearer in our communication with our PO. Of course, just like the debt itself, there is no quantifiable metric for the effectiveness of this process but my team mates seem to think that its helped, so I am inclined to believe them!
I will be keen to know how others handle tech debt in their teams so please feel free to leave a comment!
Resources:
Managing Technical Debt [Book]
Header image source.
